🔥 How to Create Your Scalable and Dedicated Qualcomm-TensorOpera AI Endpoint?
Deployment Steps on TensorOpera AI Platform (https://tensoropera.ai/home):
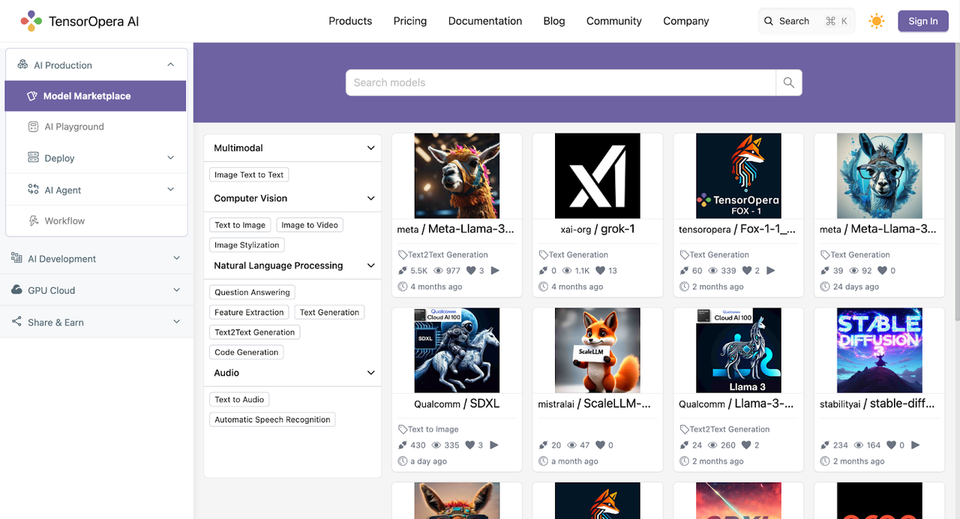
1. Go to Deploy > Endpoints > Create Endpoint
2. Select model (e.g., SDXL, Llama3-8B), version, and name your endpoint
3. Select deployment method: dedicated on TensorOpera cloud or your on-premise servers
4. Set the needed number of GPUs per replica (we recommend 1x AI 100 for Llama3 and 2x AI 100 for SDXL replica)
5. Set the number of replicas to meet your average traffic demand
6. Set the autoscale limit to meet your peak traffic variations
Customized Auto-Scaling:
1. Customize auto-scaling conditions and speed that scales replicas based on your traffic
2. Balance automatically high SLA & cost efficiency
Result:
1. Your own dedicated endpoint running on Qualcomm AI 100
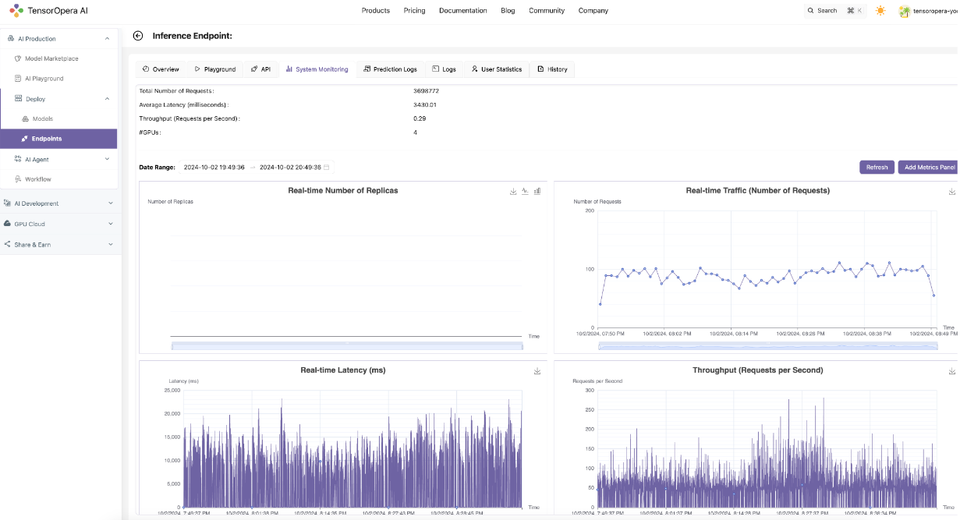
2. Advanced features: Playground, API Access, System Monitoring, Prediction Logs, User Statistics from TensorOpera AI
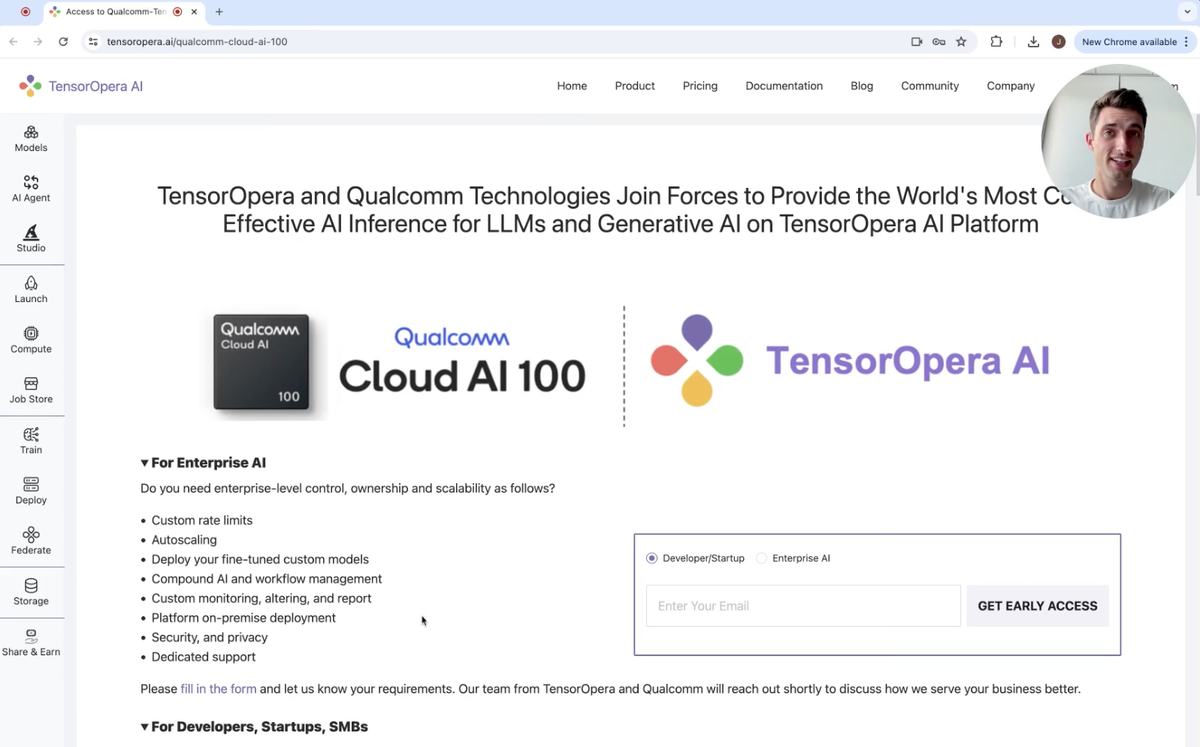
Get early access on https://tensoropera.ai/qualcomm-cloud-ai-100
Reach out to us via LinkedIn, Twitter, or join our Slack and Discord Channel.