TensorOpera Unveils Fox Foundation Model: A Pioneering Small Language Model (SLM) for Cloud and Edge
We are thrilled to introduce TensorOpera Fox-1, our cutting-edge 1.6B parameter small language model (SLM) designed to advance scalability and ownership in the generative AI landscape. TensorOpera Fox-1 is a top-performing SLM in its class, outperforming SLMs developed by industry giants like Apple, Google, and Alibaba, making it an optimal choice for developers and enterprises looking for scalable and efficient AI deployment.
By integrating Fox-1 into both the TensorOpera AI platform and the TensorOpera FedML platform, we further enable the deployment, training, and creation of AI applications across a wide range of platforms and devices. This includes everything from high-powered GPUs in the cloud to edge devices such as smartphones and AI-enabled PCs. This development highlights our commitment to delivering "Your Generative AI Platform at Scale," which promotes ownership and scalability across both cloud and edge computing environments.
Benefits of SLMs over LLMs?
SLMs are gaining popularity in the AI landscape by offering powerful capabilities with minimal computational and data requirements. This evolution is particularly significant as it opens avenues for deploying AI in various settings, from mobile devices to server constraints, all while maintaining high performance. The integration of SLMs into innovative architectures such as mixture of experts (MoE) and model federation further amplifies their utility, enabling the construction of larger, more powerful systems by synergistically combining multiple (or many) SLMs.Key advantages and promises of SLMs include:
- Efficiency and Speed: SLMs are engineered to operate with significantly reduced latency and require far less computational power compared to LLMs. This allows them to process and analyze data more quickly, dramatically enhancing both the speed and cost-efficiency of inferencing, as well as responsiveness in generative AI applications.
- Scalability across Platforms: One of the key strengths of SLMs is their versatility. These models can be deployed and trained across a myriad of platforms and devices, ranging from powerful GPUs on the cloud to edge devices like smartphones and AI PCs. This adaptability ensures that SLMs can be integrated into various technological environments, thus broadening their applicability and enhancing user accessibility.
- Integration in Composite Architectures: SLMs are particularly well-suited for integration into composite AI architectures such as Mixture of Experts (MoE) and model federation systems. These configurations utilize multiple SLMs in tandem to construct a more powerful model that can tackle more complex tasks like multilingual processing and predictive analytics from several data sources.
What is unique about TensorOpera Fox-1?
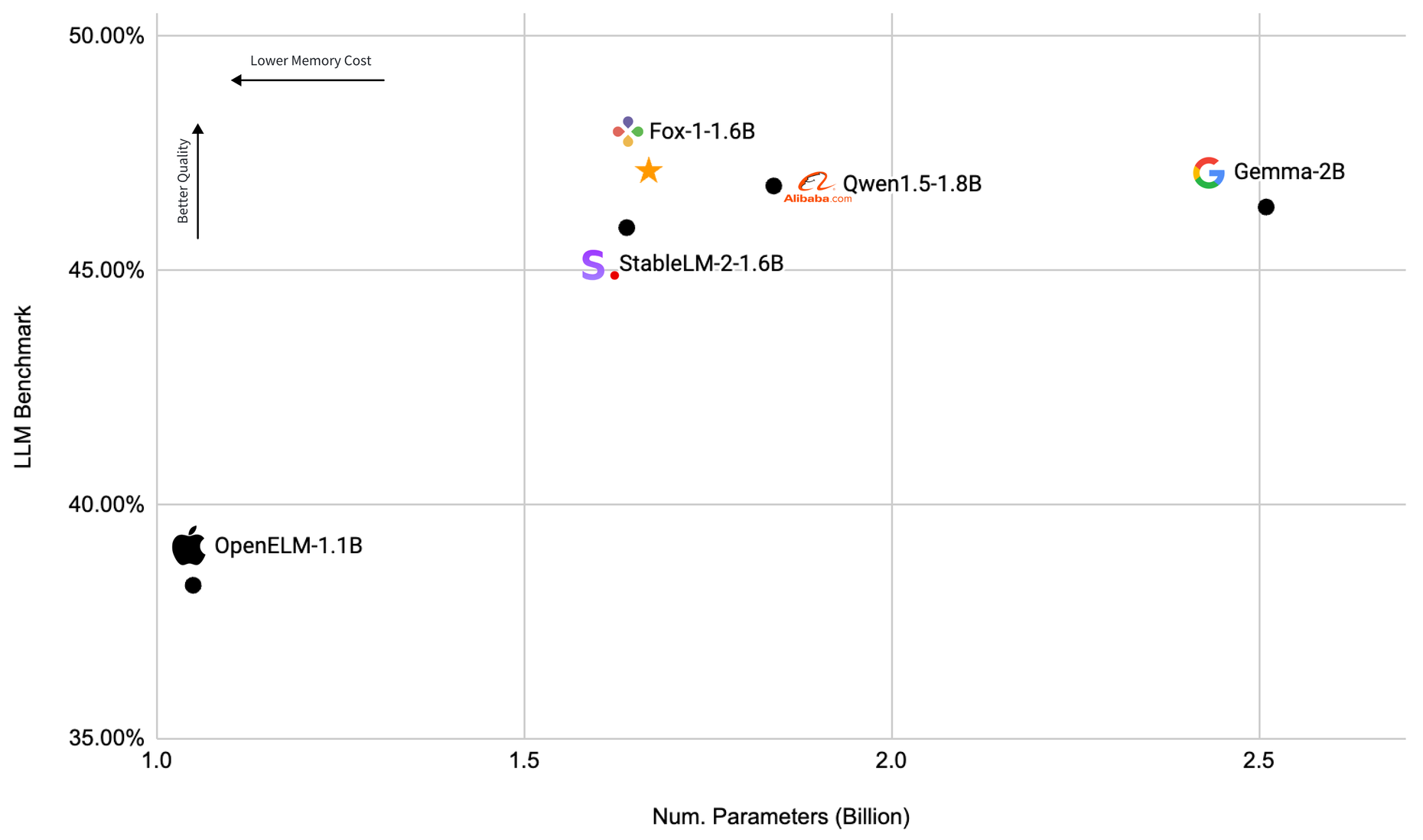
Fox-1 is a decoder-only transformer-based small language model (SLM) with 1.6B total parameters. The model was trained with a 3-stage data curriculum on 3 trillion tokens of text and code data in 8K sequence length. Fox-1 uses Grouped Query Attention (GQA) with 4 key-value heads and 16 attention heads and has a deeper architecture than other SLMs. Specifically, Fox-1 is 78% deeper than Gemma-2B, 33% deeper than Qwen1.5-1.8B and StableLM-2-1.6B, and 15% deeper than OpenELM-1.1B.
Performance Comparison of Fox-1 vs other SLMs
We evaluated Fox-1 and other SLMs on ARC Challenge (25-shot), HellaSwag (10-shot), TruthfulQA (0-shot), MMLU (5-shot), Winogrande (5-shot), and GSM8k (5-shot). We follow the Open LLM Leaderboard's evaluation setup and report the average score of the 6 benchmarks. All models are evaluated on the same machine with 8*H100 GPUs and the same software environment.
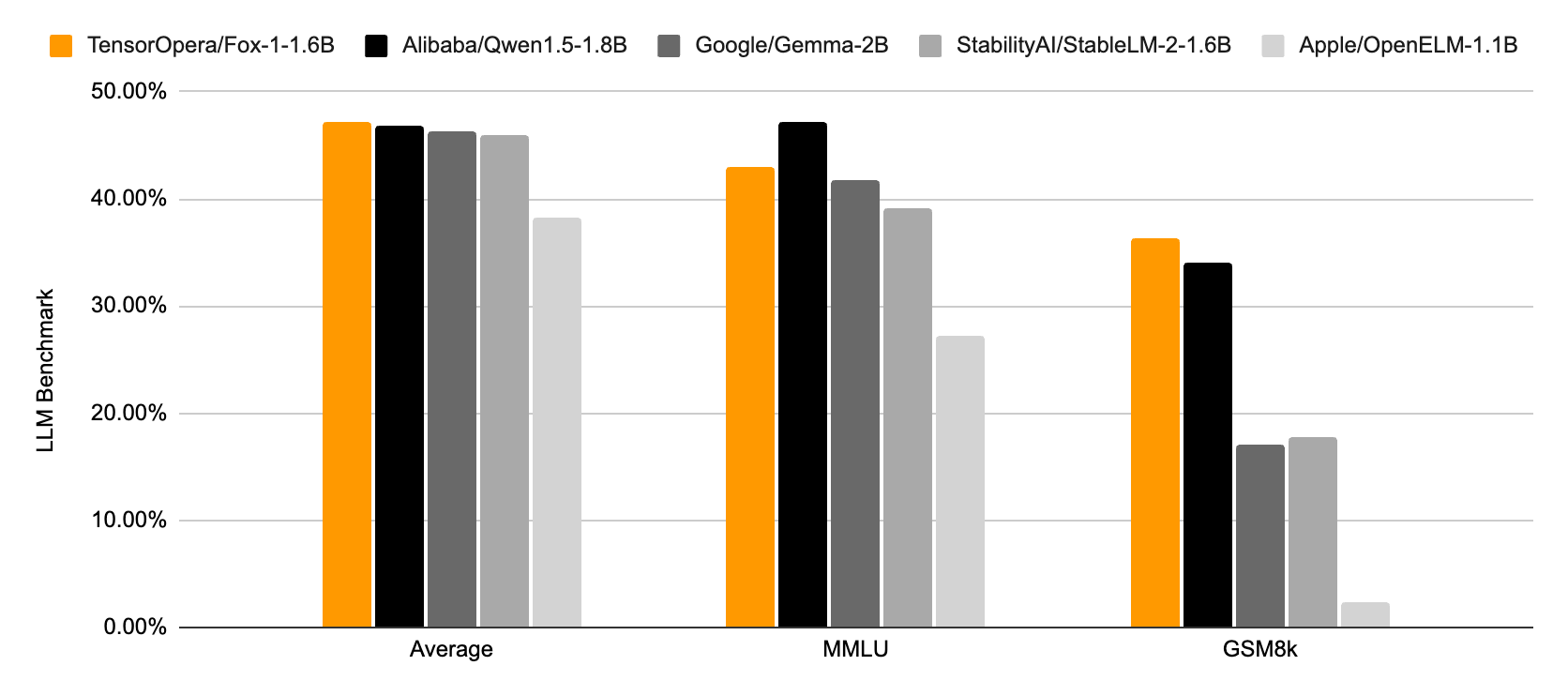
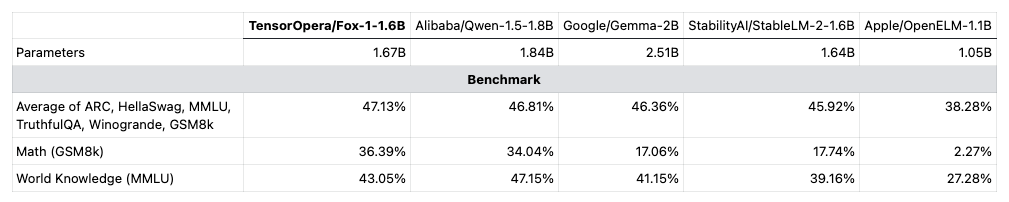
As shown in the above figure and table, Fox-1 is on par or better than Gemma-2B, Qwen1.5-1.8B, StableLM-2-1.6B, and OpenELM1.1B on standard LLM benchmarks. For GSM8k, Fox-1 achieves 36.39%, which is higher than all of our baselines. Fox-1 also outperforms Gemma-2B, StableLM-2-1.6B, and OpenELM 1.1B on MMLU despite having 50% fewer parameters than Gemma-2B.
Inference Efficiency of Fox-1
We evaluated the end-to-end inference efficiency of Fox-1, Qwen1.5-1.8B, and Gemma-2B using vLLM with the TensorOpera serving platform in BF16 precision on one Nvidia H100. This benchmark simulates real-world usage as closely as possible by sending multiple concurrent requests to the same inference server to mimic multi-user scenarios. We use the OpenOrca dataset and evaluate output tokens per user per second. Each user request contains a prompt with 234 tokens on average, and each response comprises 512 tokens.As shown in the figure below, in terms of operational efficiency, Fox-1 achieves an impressive throughput of over 200 tokens per second on the TensorOpera model serving platform, surpassing the performance of Gemma-2B and equaling that of Qwen1.5-1.8B in identical deployment environments. The high throughput of Fox-1 can largely be attributed to its architectural design, which incorporates Grouped Query Attention (GQA) for more efficient query processing. More specifically, by divining the query heads into groups where each group shares the same key-value head, Fox-1 significantly improves inference latency and enhances response times.
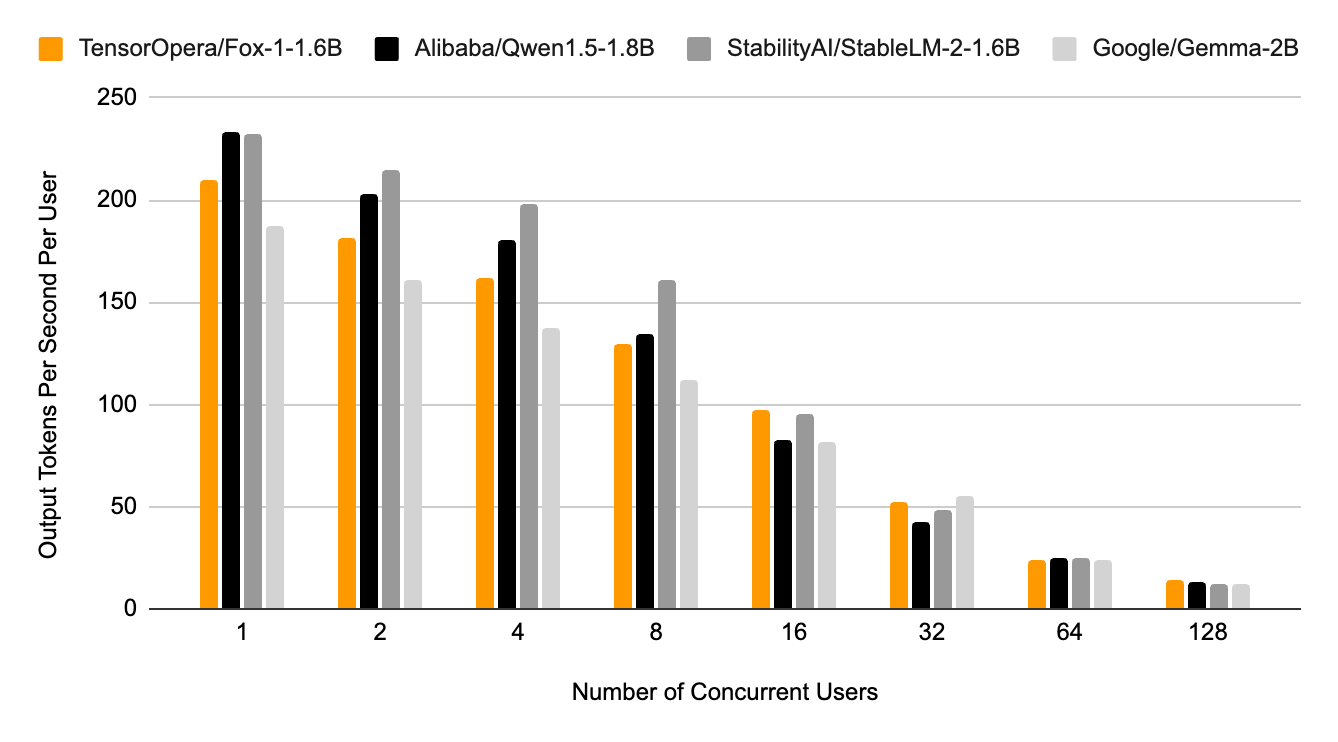
With FP16 precision, Fox-1 becomes comparable for on-device deployment with 3703MiB GPU Memory, while Qwen1.5-1.8B, StableLM-2-1.6B, and Gemma-2B, respectively, need 4739MiB, 3852MiB, and 5379MiB.
Integration of Fox-1 into the TensorOpera Product Suite
The integration of Fox-1 into both the TensorOpera AI Platform and the TensorOpera FedML Platform further enhances its versatility, enabling its deployment and training across both cloud and edge computing environments. It empowers AI developers to train and build their models and applications on the cloud utilizing the comprehensive capabilities of the TensorOpera AI Platform, and then deploy, personalize, and monitor these solutions directly onto smartphones and AI-enabled PCs via the TensorOpera FedML platform. This approach offers cost efficiency, enhanced privacy, and personalized user experiences, all within a unified platform that facilitates seamless collaboration between cloud and edge environments.
Getting Started with Fox-1
We are releasing the base version Fox-1 under the Apache 2.0 license. This means you can freely use it for production and research. The instruction-tuned version will be released soon. The model can be accessed from the TensorOpera AI Platform and Hugging Face.
Stay tuned for upcoming posts in the coming weeks on the deployment and fine-tuning of Fox-1 directly on the TensorOpera AI platform.
TensorOpera Announces the SLM Pioneer Fox-1