
Serverless Training Cloud Service on FEDML Nexus AI with Seamless Experimental Tracking

We are excited to introduce our “Training as a Cloud Service” at FEDML Nexus AI platform. It provides a variety of GPU types (A100, H100, A6000, RTX4090, etc.) for developers to train your model at any time in a serverless manner. Developers only pay per usage. It includes the following features:
- Cost-effective training: Developers do not need to rent or purchase GPUs, developers can initiate serverless training tasks at any time, and developers only need to pay according to the usage time;
- Flexible Resource Management: Developers can also create a cluster to use fixed machines and support the cluster autostop function (such as automatic shutdown after 30 minutes) to help you save the cost loss caused by forgetting to shut down the idle resources.
- Simplified Code Setup: You do not need to modify your python training source code, you only need to specify the path of the code, environment installation script, and the main entrance through the YAML file
- Comprehensive Tracking: The training process includes rich experimental tracking functions, including Run Overview, Metrics, Logs, Hardware Monitoring, Model, Artifacts, and other tracking capabilities. You can use the API provided by FEDML Python Library for experimental tracking, such as fedml.log
- GPU Availability: There are many GPU types to choose from. You can go to Secure Cloud or Community Cloud to view the type and set it in the YAML file to use it.
We will introduce how simple it is as follows:
- Zero-code Serverless LLM Training on FEDML Nexus AI
- Training More GenAI Models with FEDML Launch and Pre-built Job Store
- Experiment Tracking for Large-scale Distributed Training
- Train on Your Own GPU cluster
Platform: https://fedml.ai
GitHub: https://github.com/FedML-AI
Zero-code Serverless LLM Training on FEDML Nexus AI
As an example of applying FEDML Launch for training service, LLM Fine-tune is the feature of FEDML Studio that is responsible for serverless model training. It is a no-code LLM training platform. Developers can directly specify open-source models for fine-tuning or model Pre-training.
Step 1. Select a model to build a new run
There are two choices for specifying the model to train:
1) Select Default base model from Open Source LLMs
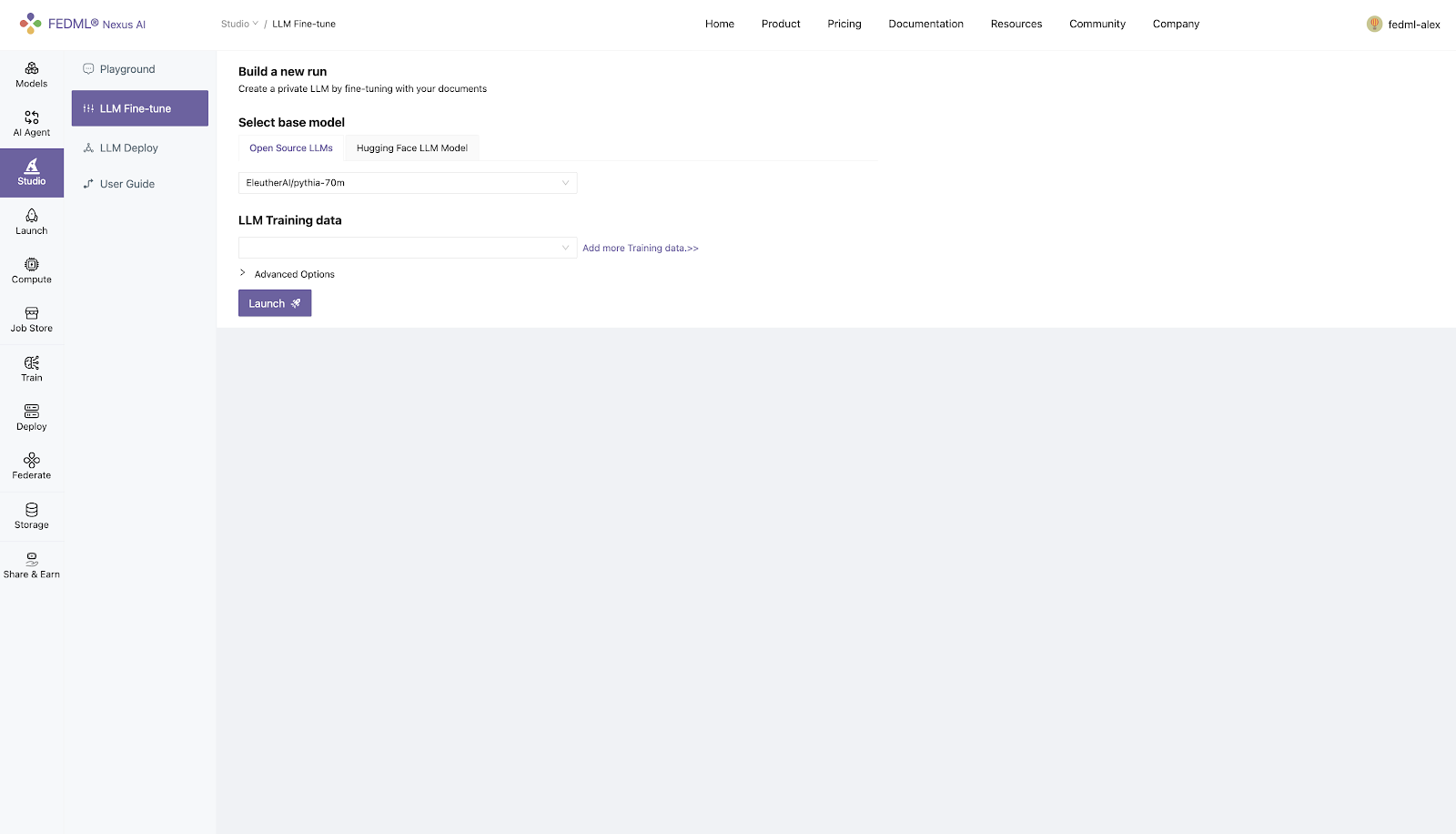
2) Specifying HuggingFace LLM model path
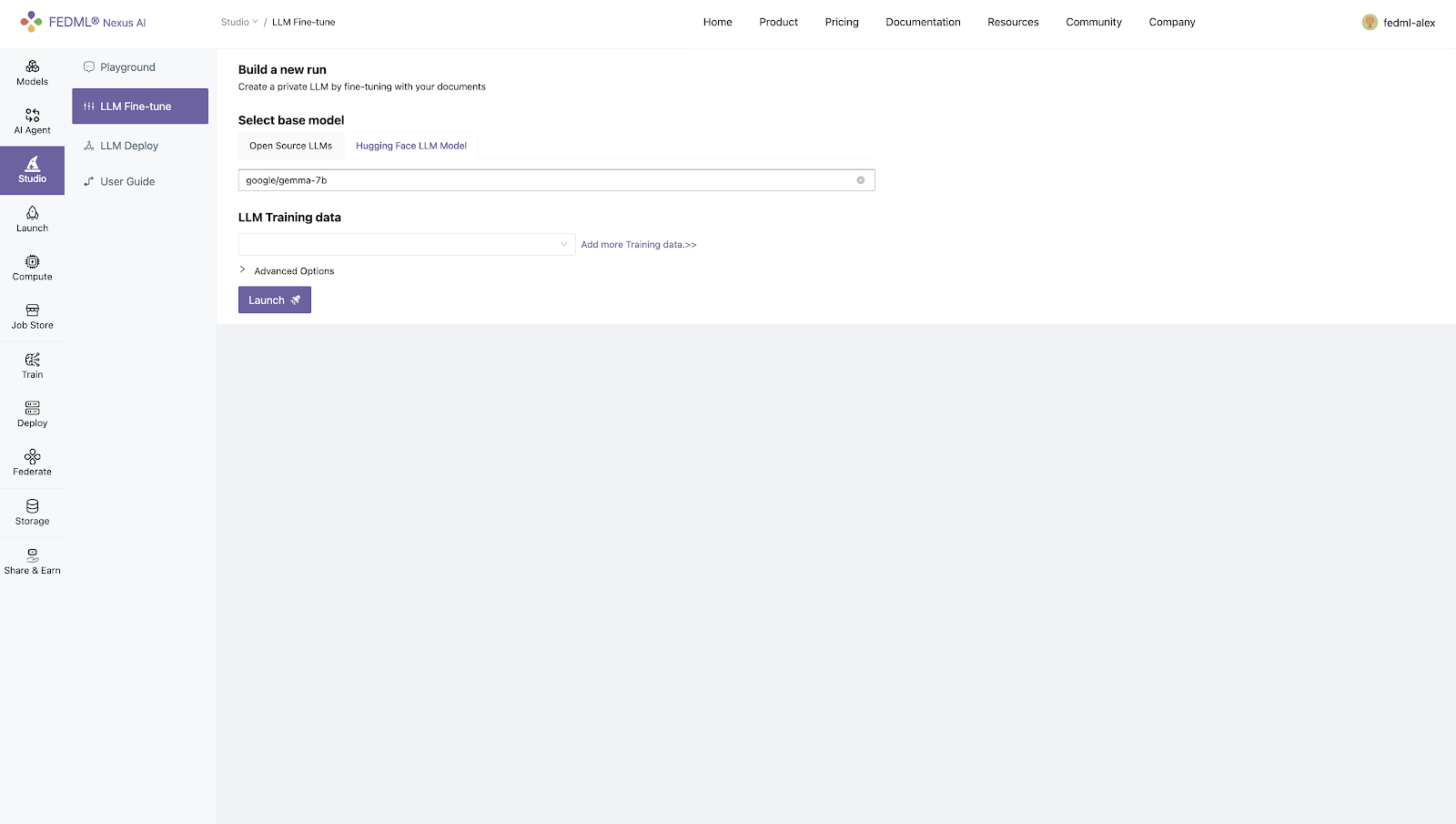
Step 2. Prepare training data
There are three ways to prepare the training data.
1) Select the default data experience platform
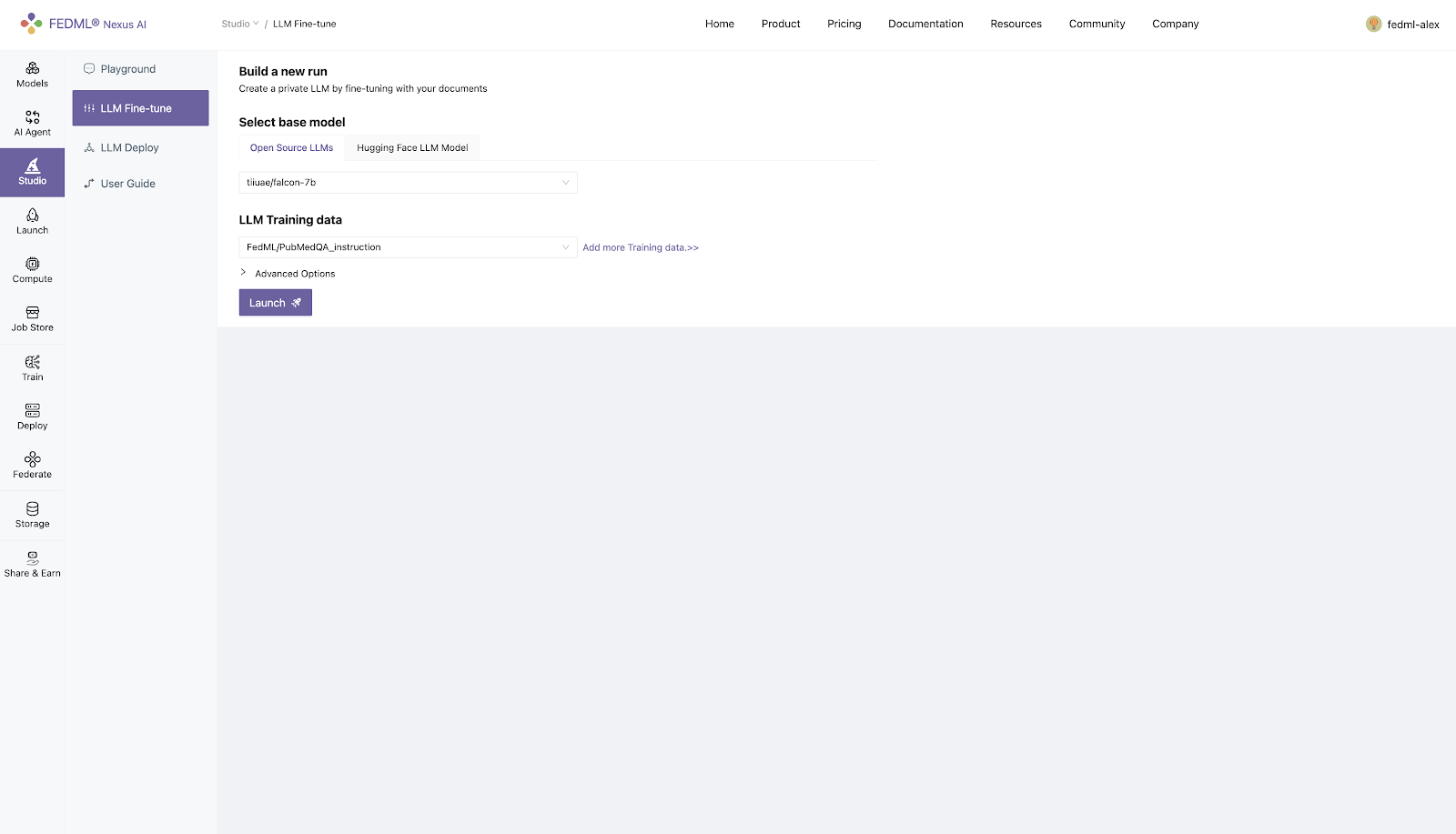
2) Customized training data can be uploaded through the storage module
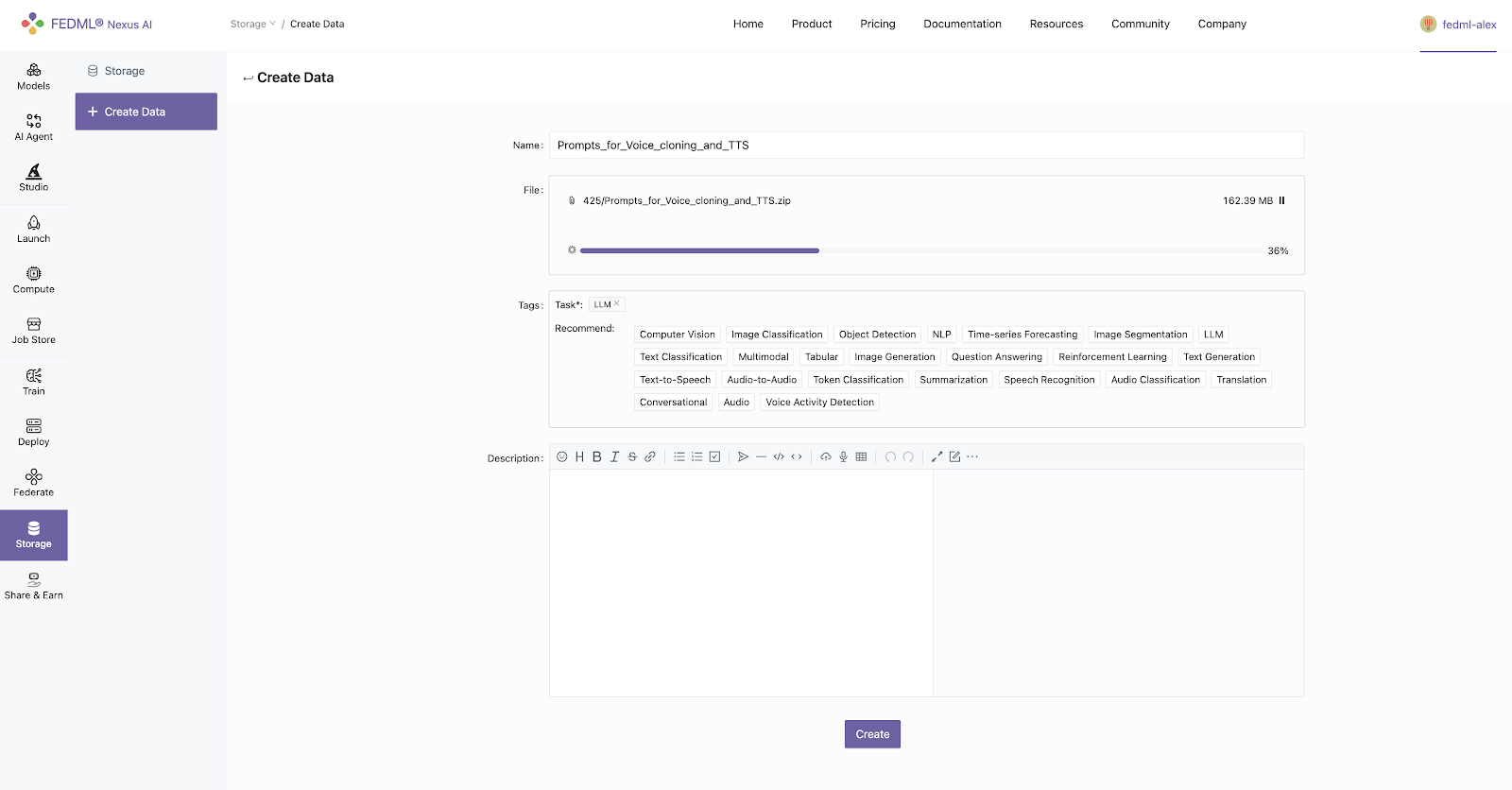
3) Data upload API: fedml.api.storage
fedml storage upload '/path/Prompts_for_Voice_cloning_and_TTS'
Uploading Package to Remote Storage: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 42.0M/42.0M [00:36<00:00, 1.15MB/s]
Data uploaded successfully. | url: https://03aa47c68e20656e11ca9e0765c6bc1f.r2.cloudflarestorage.com/fedml/3631/Prompts_for_Voice_cloning_and_TTS.zip?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=52d6cf37c034a6f4ae68d577a6c0cd61%2F20240307%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20240307T202738Z&X-Amz-Expires=604800&X-Amz-SignedHeaders=host&X-Amz-Signature=bccabd11df98004490672222390b2793327f733813ac2d4fac4d263d50516947
Step 3. Hyperparameter Setting (Optional)
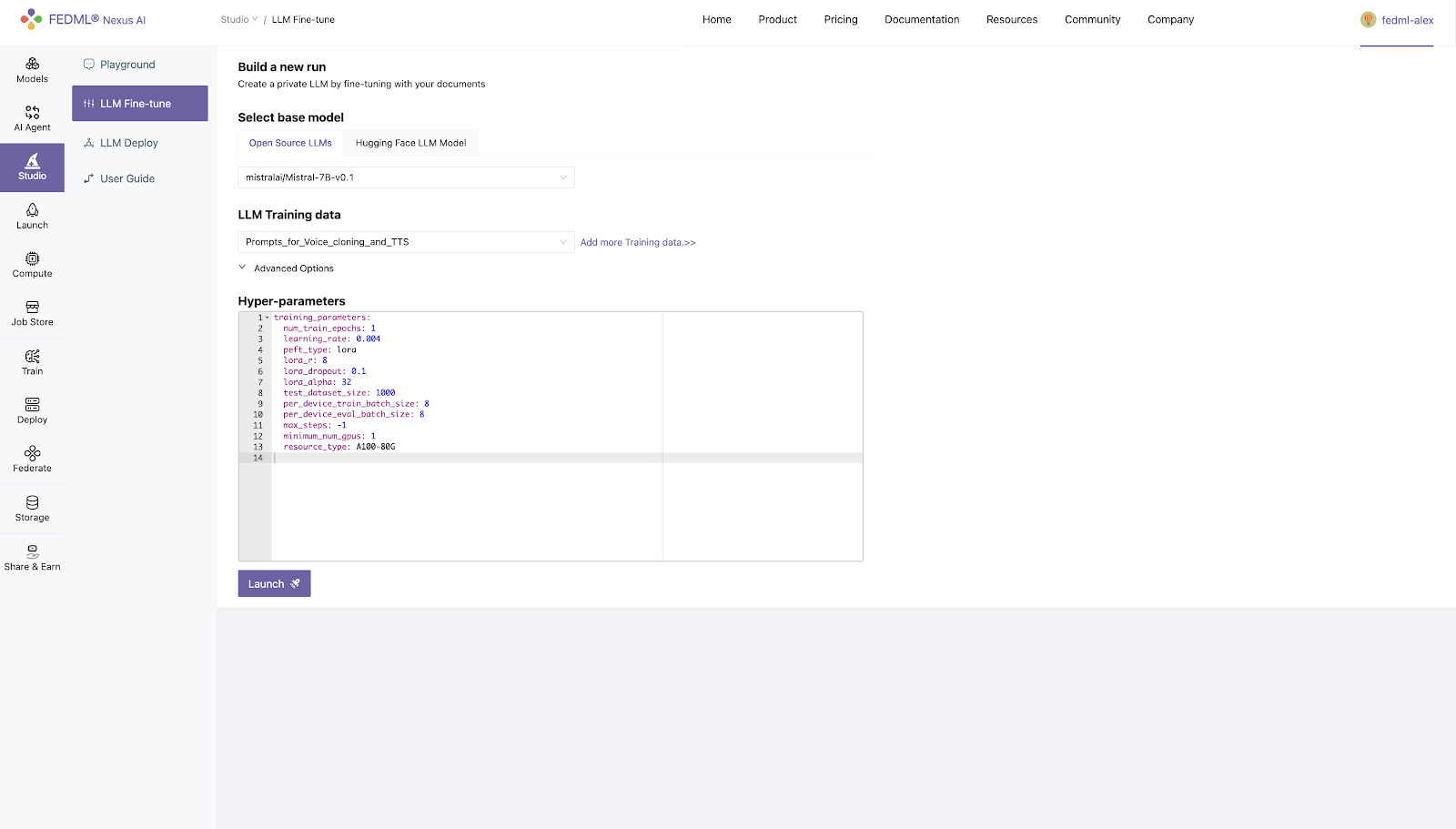
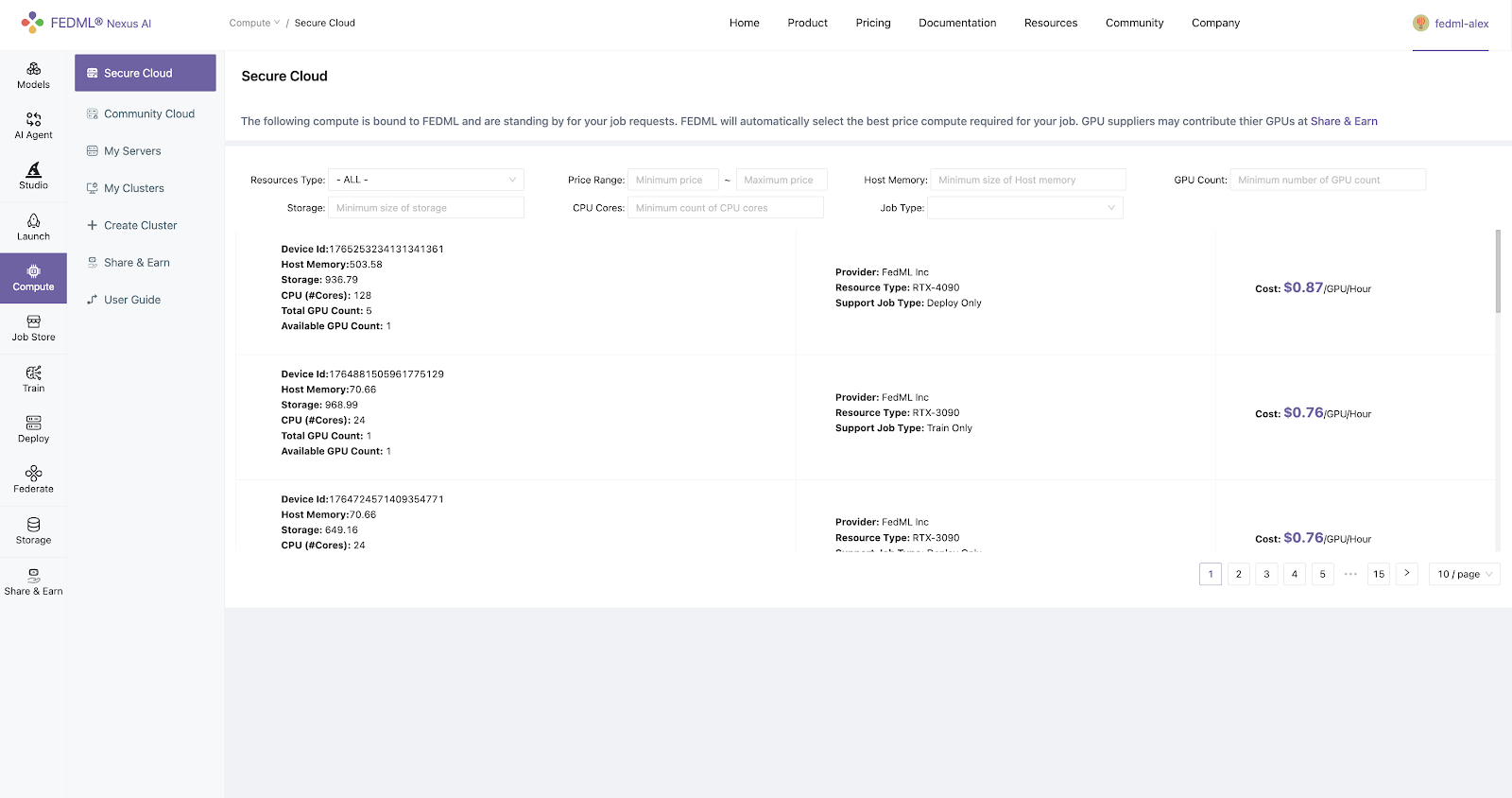
Step 4. Select GPU Resource Type (Optional)
The GPU resource type can be found through the Compute - Secure Cloud page
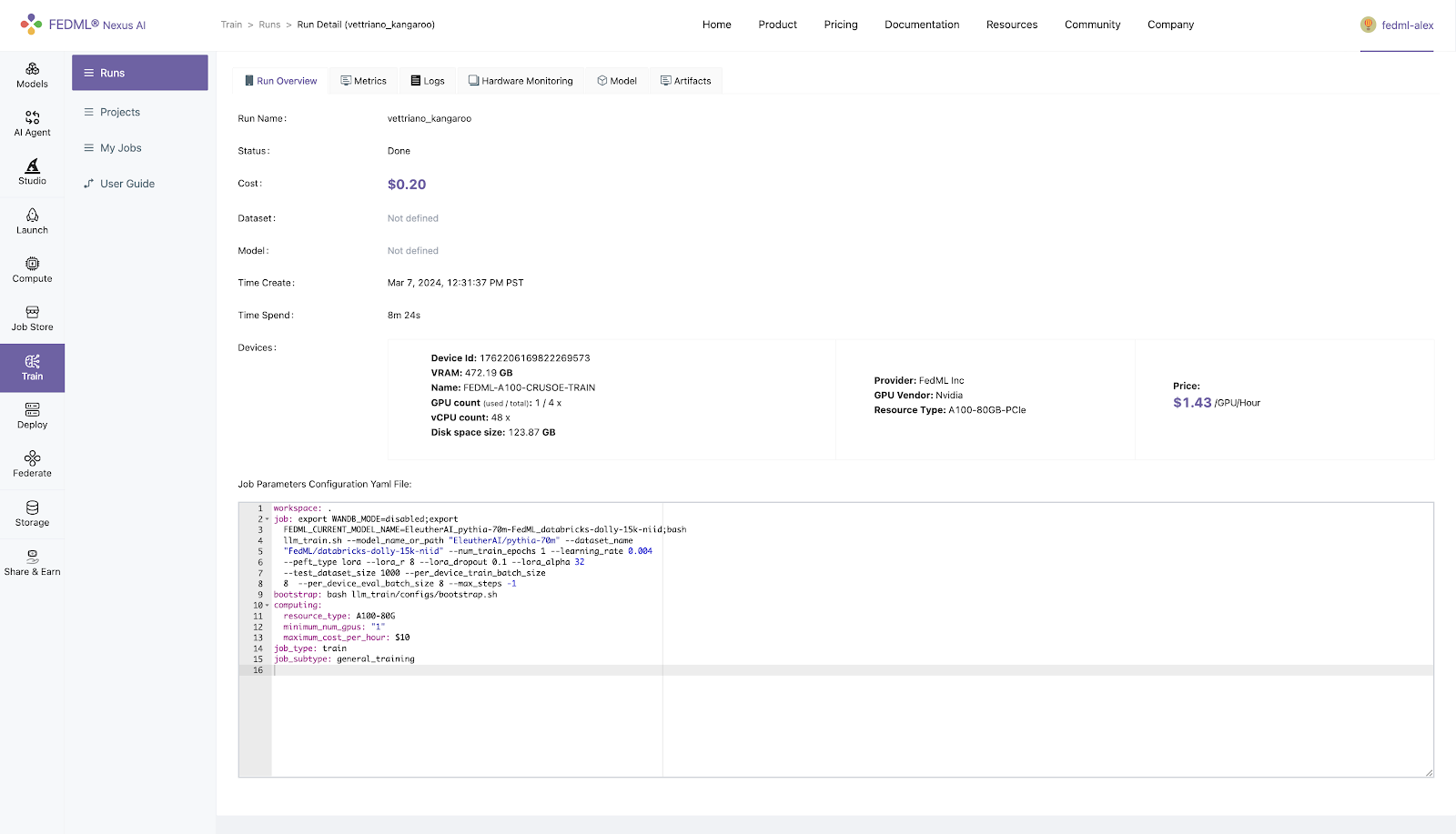
Step 5. Initiate Training and Track Experimental Results
Training More GenAI Models with FEDML Launch and Pre-built Job Store
Besides the zero-code training job experience, we also provide FEMDL Launch to launch any training job on FEDML Nexus AI. For more details, please read another blog: https://blog.fedml.ai/fedml-launch/. Here, we mainly introduce how to run pre-built jobs on FEDML Nexus AI platform.
Taking a pre-built job for GaLore (https://github.com/jiaweizzhao/galore), an efficient training method for LLM on RTX4090, as an example. A day after it released source code on GitHub, FEDML Team incorporated GaLore training as part of our Job Store. Now developers can launch and customize on top of the example GaLore jobs and enjoy freedom from Out-of-Memory fear.
The instructions to launch GaLore pre-built job are as follows:
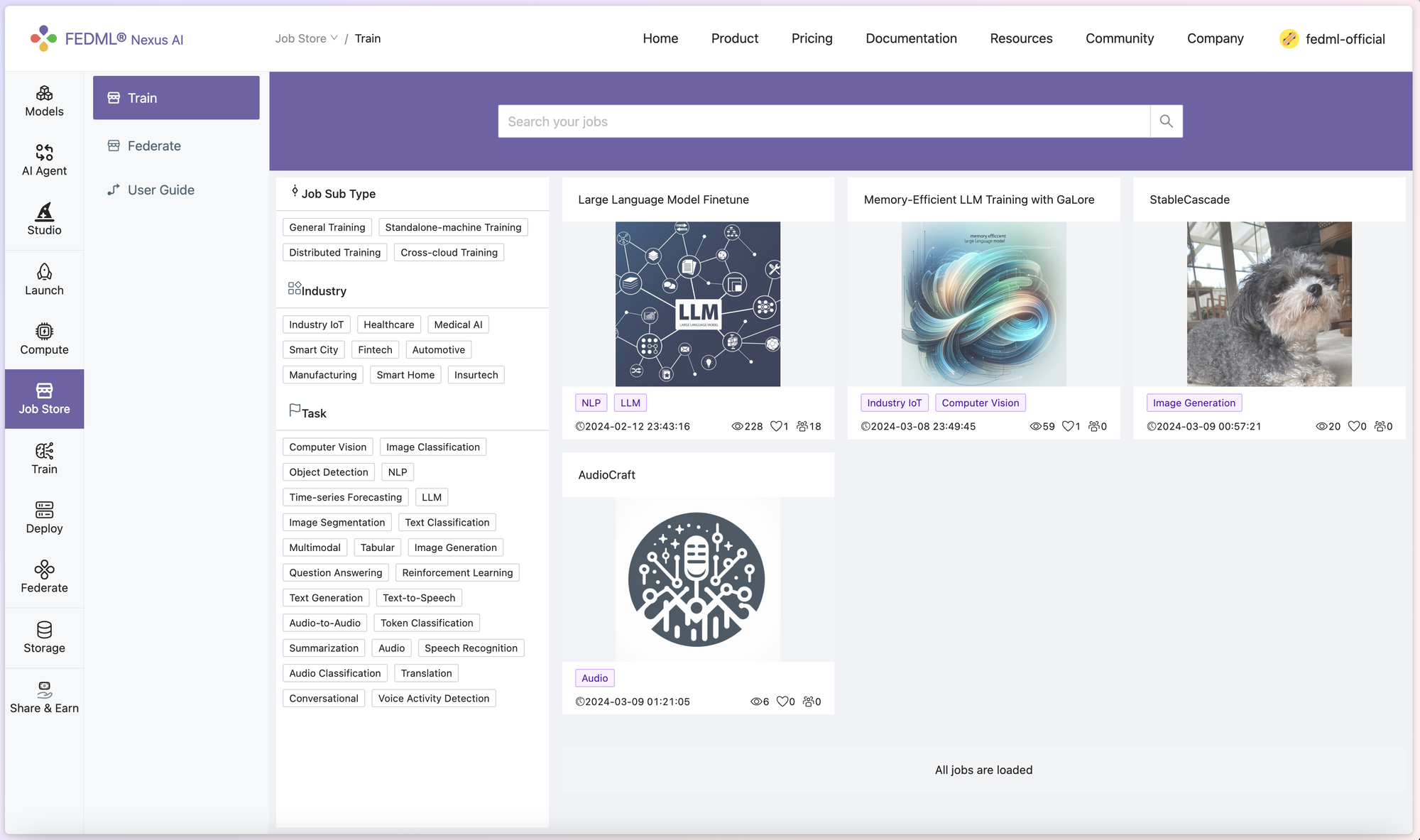
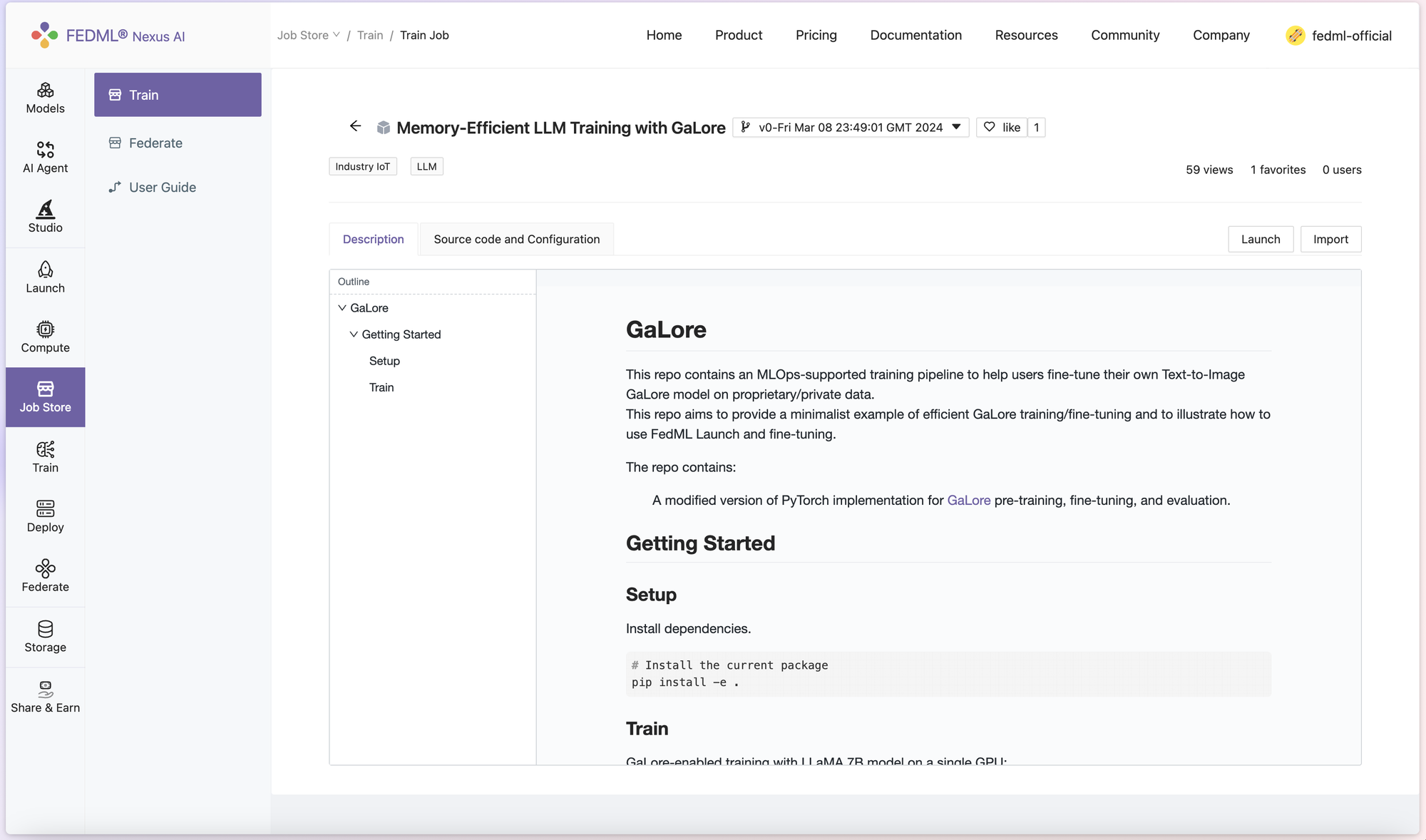
1. On FedML official website (https://fedml.ai/home), you can head to Launch > Job Store > Train, and look for Memory-Efficient LLM Training with GaLore job. The Description tab shows some basic usage for the code, referencing the original GaLore project's README. In the Source Code and Configuration tab, you can examine a more detailed layout and setup of the architecture.
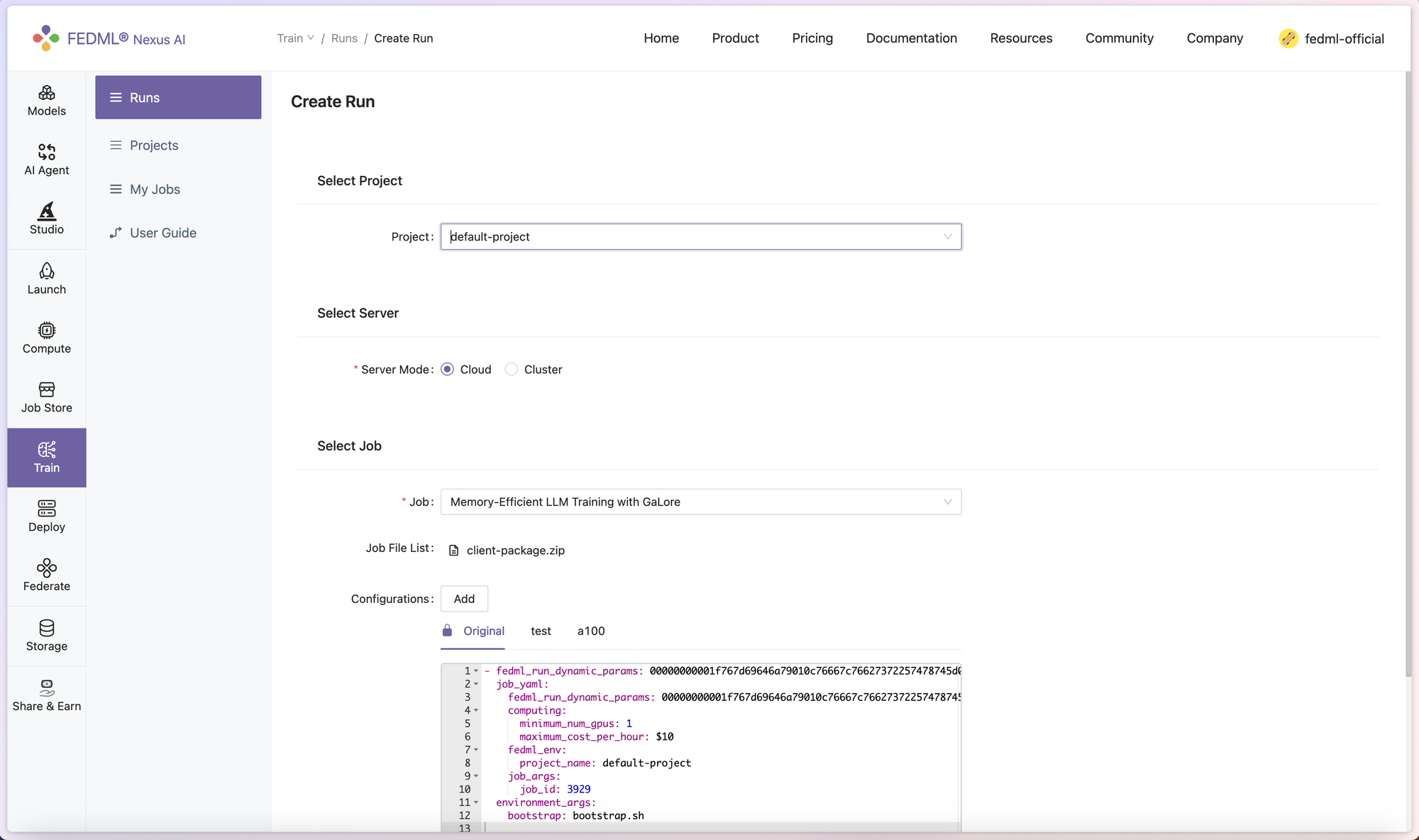
2. Hit the Launch button on the top right, users will be prompted to enter the configuration for the job. Under the Select Job section, click Add, and add “resource_type: RTX-4090” in the job_yaml > computing section to specify using RTX 4090 for training. Please check the resource type list at https://fedml.ai/compute/secure (check the value of Resource Type in each GPU item), or directly visit https://fedml.ai/launch/accelerator_resource_type?_t=1710889566178.
3. Once done filling out the hyperparameters, you should be able to launch a full-scale GaLore + Checkpointing Activation pre-training for the LLaMA 7B model with a batch size of 16. Then you can find your experimental tracking results at https://fedml.ai/train/my-runs (see more details on the Section "Experiment Tracking for Large-scale Distributed Training")
Experiment Tracking for Large-scale Distributed Training
Running remote tasks often requires a transparent monitoring environment to facilitate troubleshooting and real-time analysis of machine learning experiments. This section guides through the monitoring capabilities of a launched job.
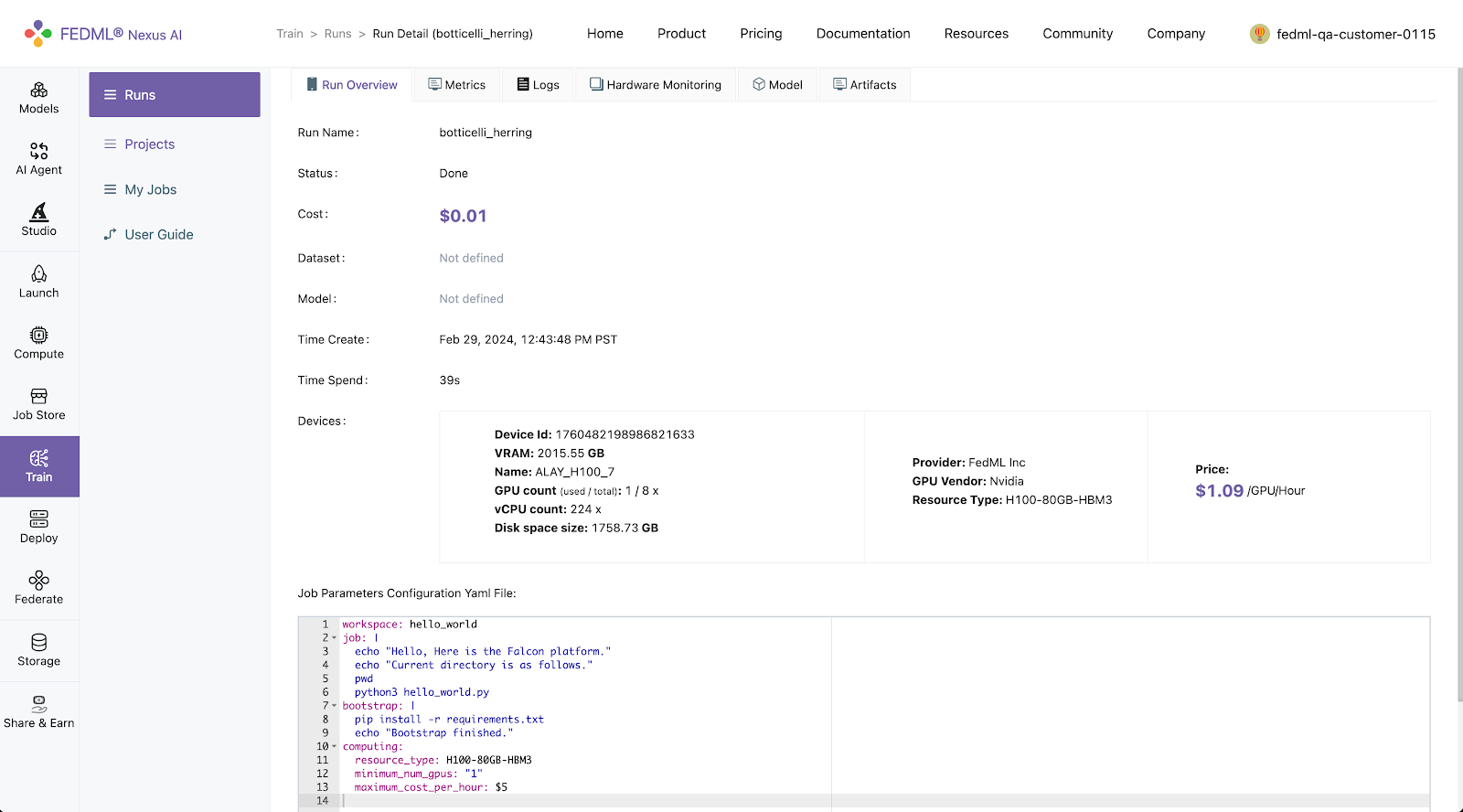
Run Overview
Log into to the FEDML Nexus AI Platform (https://fedml.ai) and go to Train > Runs. And select the run you just launched and click on it to view the details of the run.
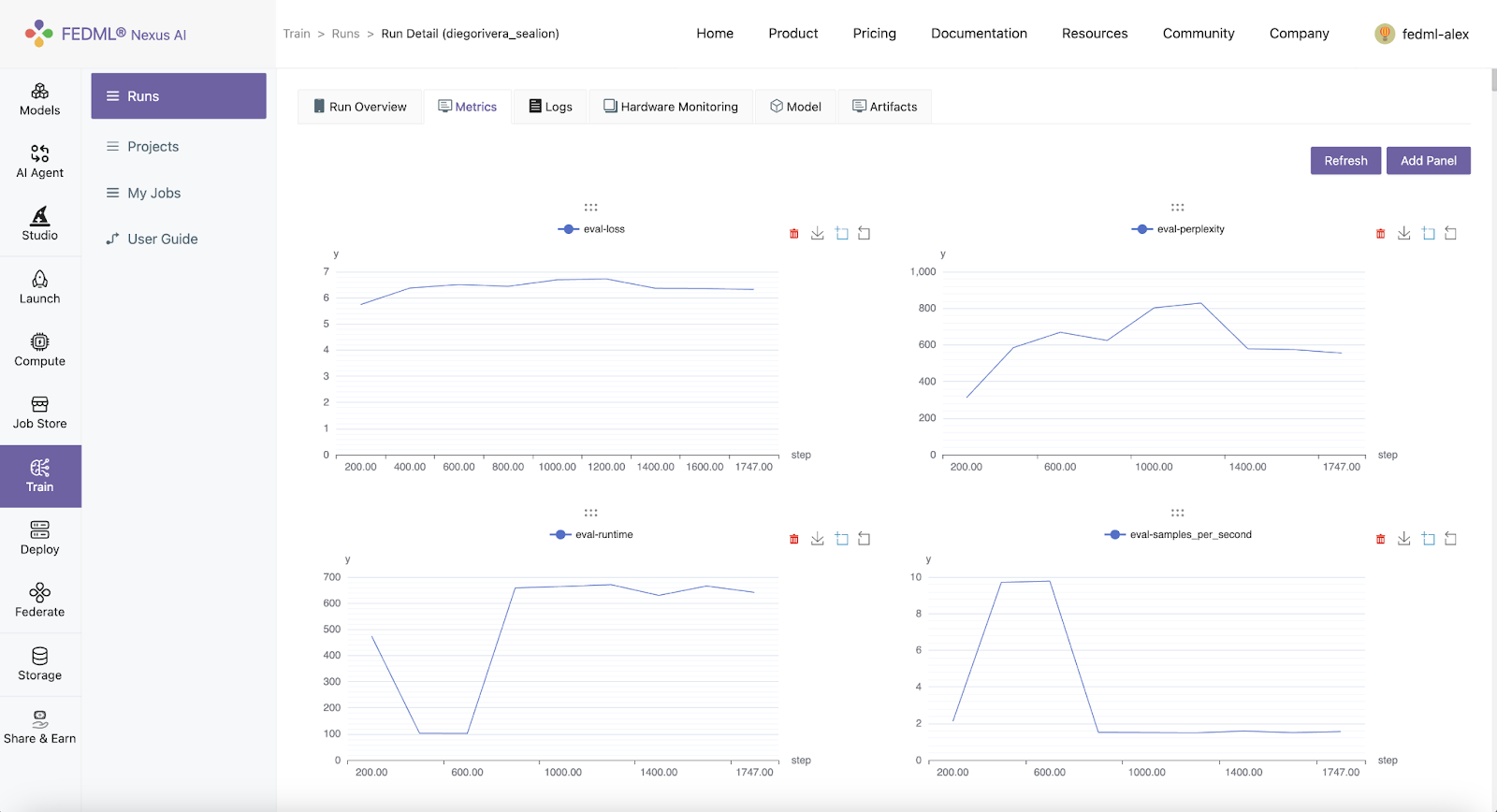
Metrics
FedML offers a convenient set of APIs for logging metrics. The execution code can utilize these APIs to log metrics during its operation.
fedml.log()
log dictionary of metric data to the FEDML Nexus AI Platform.
Usage
fedml.log(
metrics: dict,
step: int = None,
customized_step_key: str = None,
commit: bool = True) -> None
Arguments
- metrics (dict): A dictionary object for metrics, e.g., {"accuracy": 0.3, "loss": 2.0}.
- step (int=None): Set the index for current metric. If this value is None, then step will be the current global step counter.
- customized_step_key (str=None): Specify the customized step key, which must be one of the keys in the metrics dictionary.
- commit (bool=True): If commit is False, the metrics dictionary will be saved to memory and won't be committed until commit is True.
Example:
fedml.log({"ACC": 0.1})
fedml.log({"acc": 0.11})
fedml.log({"acc": 0.2})
fedml.log({"acc": 0.3})
fedml.log({"acc": 0.31}, step=1)
fedml.log({"acc": 0.32, "x_index": 2}, step=2, customized_step_key="x_index")
fedml.log({"loss": 0.33}, customized_step_key="x_index", commit=False)
fedml.log({"acc": 0.34}, step=4, customized_step_key="x_index", commit=True)
Metrics logged using fedml.log() can be viewed under Runs > Run Detail > Metrics on FEDML Nexus AI Platform.
Logs
You can query the realtime status of your run on your local terminal with the following command.
fedml run logs -rid <run_id>
Additionally, logs of the run also appear in realtime on the FEDML Nexus AI Platform under the Runs > Run Detail > Logs
Hardware Monitoring
The FEDML library automatically captures hardware metrics for each run, eliminating the need for user code or configuration. These metrics are categorized into two main groups:
- Machine Metrics: This encompasses various metrics concerning the machine's overall performance and usage, encompassing CPU usage, memory consumption, disk I/O, and network activity.
- GPU Metrics: In environments equipped with GPUs, FEDML seamlessly records metrics related to GPU utilization, memory usage, temperature, and power consumption. This data aids in fine-tuning machine learning tasks for optimized GPU-accelerated performance.
Model Checkpoint:
FEDML additionally provides an API for logging models, allowing users to upload model artifacts.
fedml.log_model()
Log model to the FEDML Nexus AI Platform (fedml.ai).
fedml.log_model(
model_name,
model_file_path,
version=None) -> None
Arguments
- model_name (str): model name.
- model_file_path (str): The file path of model name.
- version (str=None): The version of FEDML Nexus AI Platform, options: dev, test, release. Default is release (fedml.ai).
Examples
fedml.log_model("cv-model", "./cv-model.bin")
Models logged using fedml.log_model() can be viewed under Runs > Run Detail > Model on FEDML Nexus AI Platform
Artifacts:
Artifacts, as managed by FEDML, encapsulate information about items or data generated during task execution, such as files, logs, or models. This feature streamlines the process of uploading any form of data to the FEDML Nexus AI Platform, facilitating efficient management and sharing of job outputs. FEDML facilitates the uploading of artifacts to the FEDML Nexus AI Platform through the following artifact api:
fedml.log_artifact()
log artifacts to the FEDML Nexus AI Platform (fedml.ai), such as file, log, model, etc.
fedml.log_artifact(
artifact: Artifact,
version=None,
run_id=None,
edge_id=None) -> None
Arguments
- artifact (Artifact): An artifact object represents the item to be logged, which could be a file, log, model, or similar.
- version (str=None): The version of FEDML Nexus AI Platform, options: dev, test, release. Default is release (fedml.ai).
- run_id (str=None): Run id for the artifact object. Default is None, which will be filled automatically.
- edge_id (str=None): Edge id for current device. Default is None, which will be filled automatically.
Artifacts logged using fedml.log_artifact() can be viewed under Runs > Run Detail > Artifacts on FEDML Nexus AI Platform.
Train on Your Own GPU cluster
You can also build your own cluster and launch jobs there. The GPU nodes in the cluster can be GPU instances launched under your AWS/GCP/Azure account or your in-house GPU devices. The workflow is as follows.
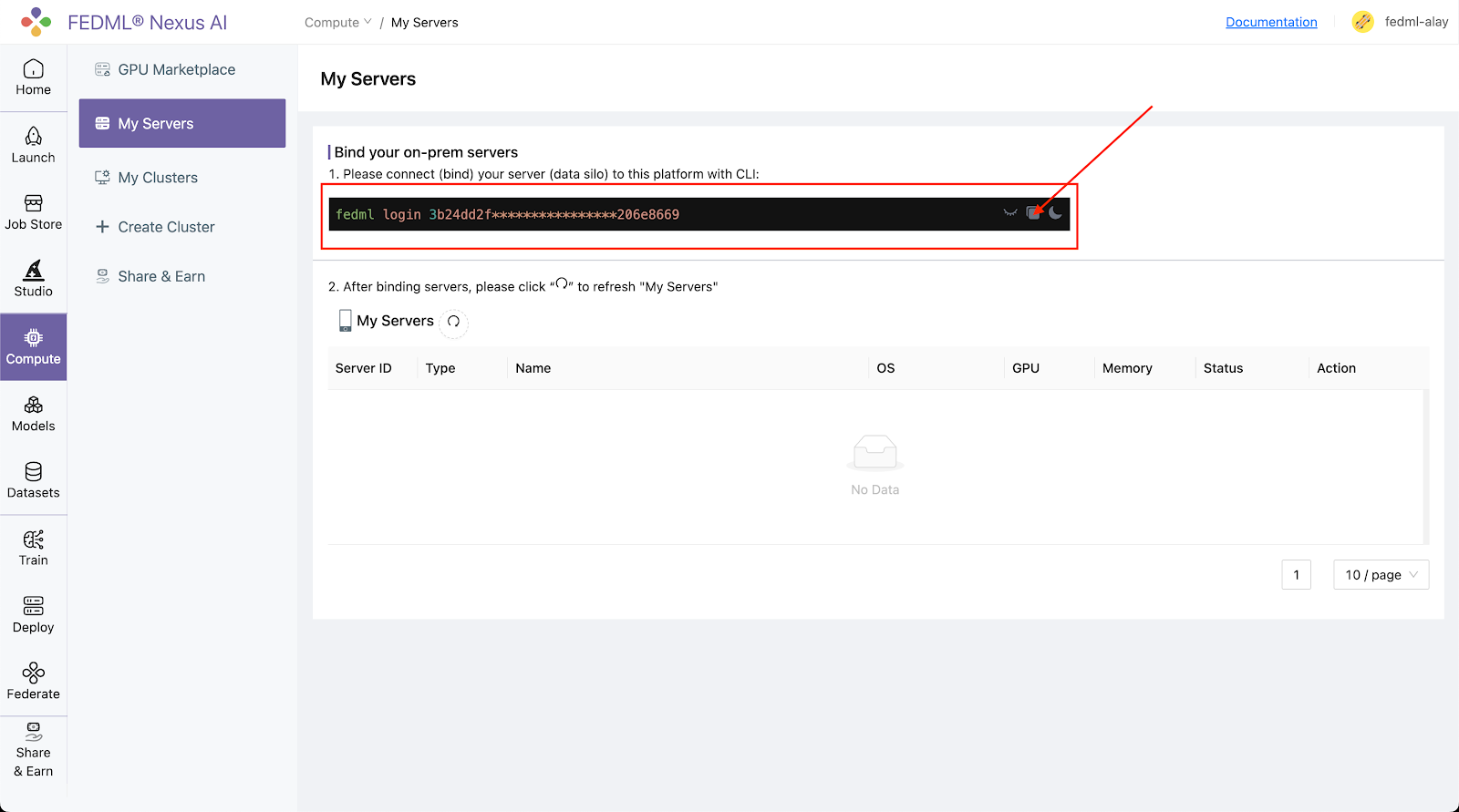
Step 1. Bind the machines on the Platform
Log into the platform, head to the Compute / My Servers Page and copy the fedml login command:
Step 2. SSH into your on-prem devices and do the following individually for each device:
Install the fedml library if not installed already:
pip install fedml
Run the login command copied from the platform:
fedml login 3b24dd2f****206e8669
It should show something similar as below:
(fedml) alay@a6000:~$ fedml login 3b24dd2f9b3e478084c517bc206e8669 -v dev
Welcome to FedML.ai!
Start to login the current device to the MLOps (https://fedml.ai)...
(fedml) alay@a6000:~$ Found existing installation: fedml 0.8.7
Uninstalling fedml-0.8.7:
Successfully uninstalled fedml-0.8.7
Looking in indexes: https://test.pypi.org/simple/, https://pypi.org/simple
Collecting fedml==0.8.8a156
Obtaining dependency information for fedml==0.8.8a156 from https://test-files.pythonhosted.org/packages/e8/44/06b4773fe095760c8dd4933c2f75ee7ea9594938038fb8293afa22028906/fedml-0.8.8a156-py2.py3-none-any.whl.metadata
Downloading https://test-files.pythonhosted.org/packages/e8/44/06b4773fe095760c8dd4933c2f75ee7ea9594938038fb8293afa22028906/fedml-0.8.8a156-py2.py3-none-any.whl.metadata (4.8 kB)
Requirement already satisfied: numpy>=1.21 in ./.pyenv/versions/fedml/lib/python3.10/site-packages (from fedml==0.8.8a156
.
.
.
.
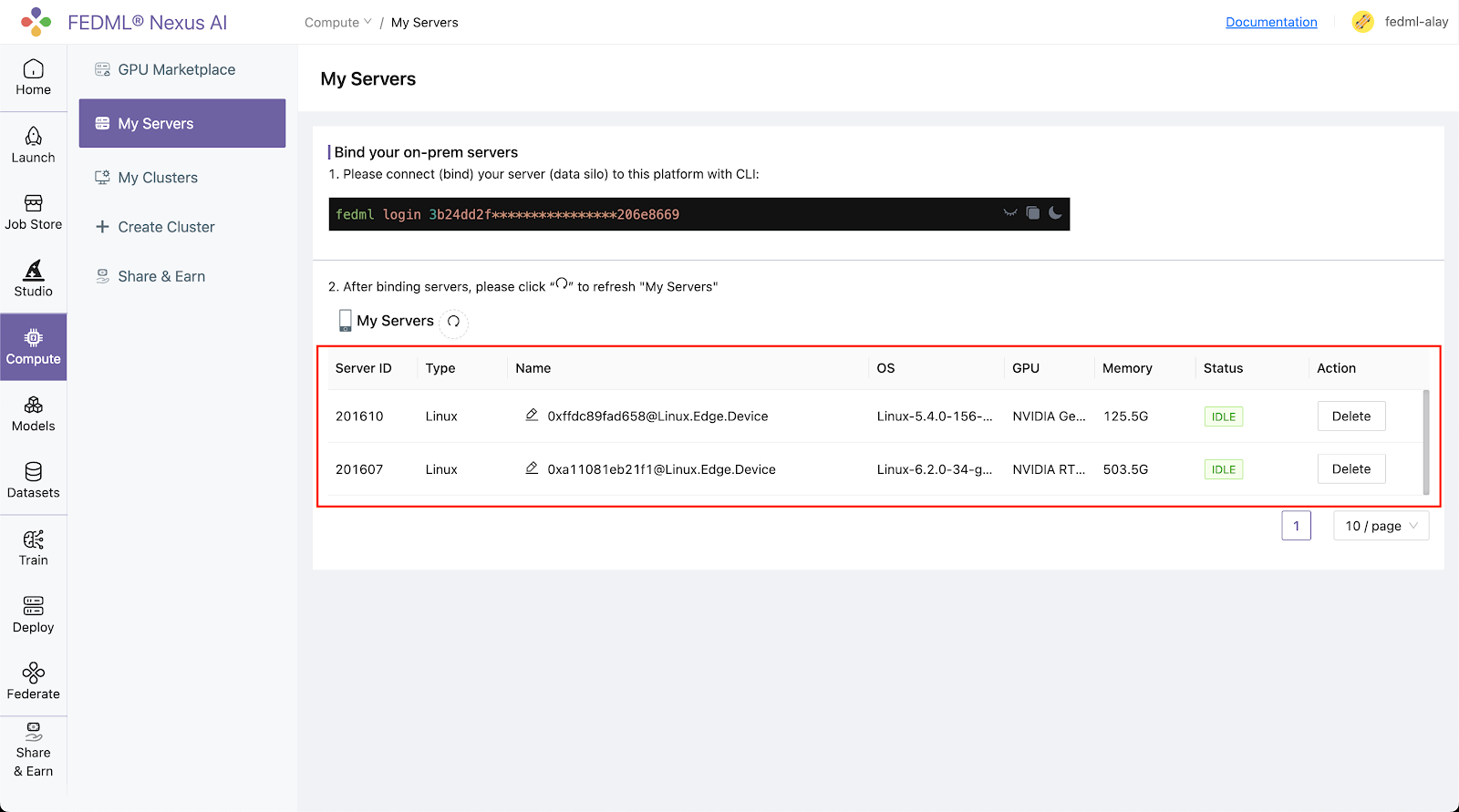
Congratulations, your device is connected to the FedML MLOps platform successfully!
Your FedML Edge ID is 201610, unique device ID is 0xffdc89fad658@Linux.Edge.Device
Head back to the Compute / My Servers page on platform and verify that the devices are bounded to the FEDML Nexus AI Platform:
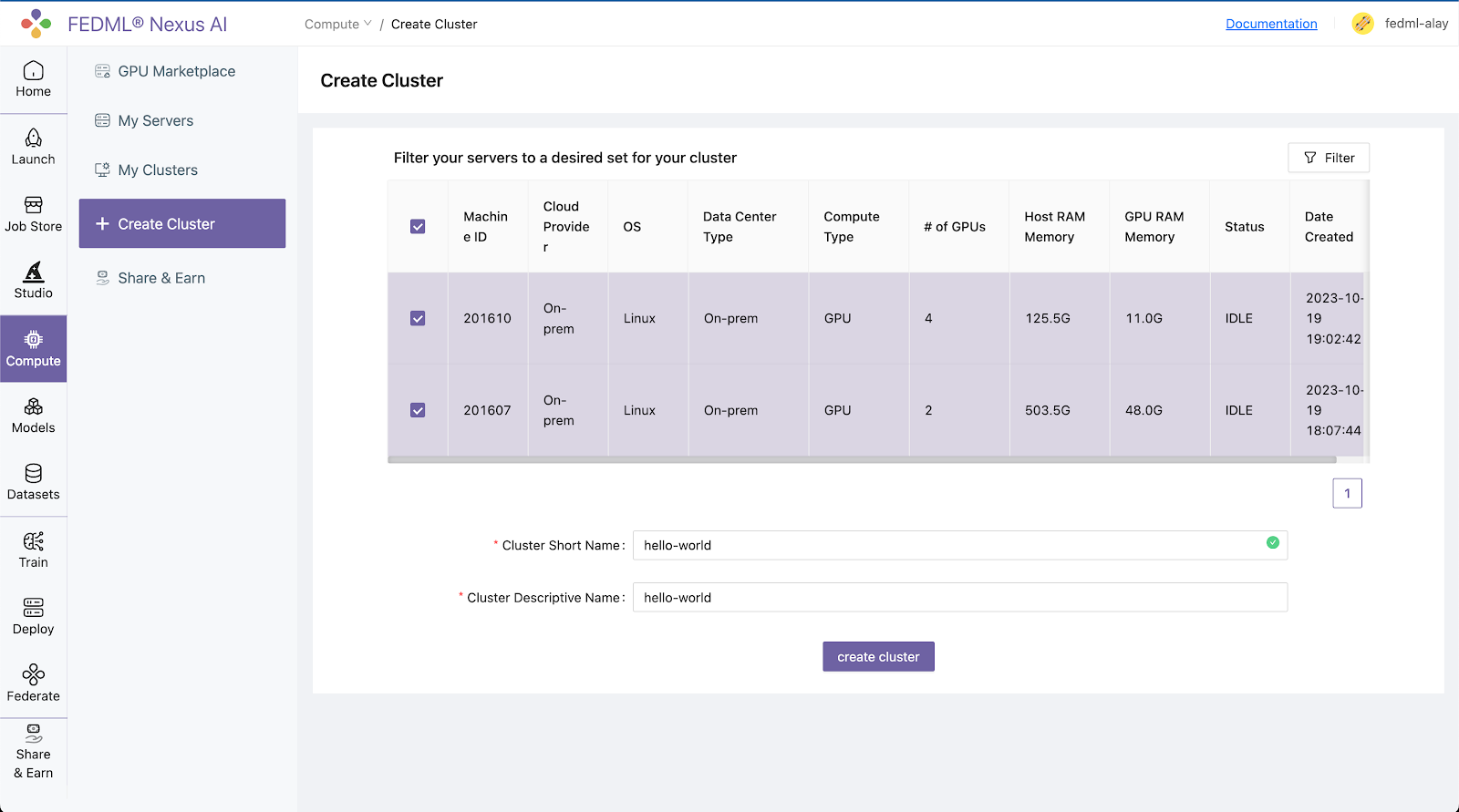
Step 3. Create a cluster of your servers bounded to the FEDML Nexus AI Platform:
Navigate to the Compute / Create Clusters page and create a cluster of your servers:
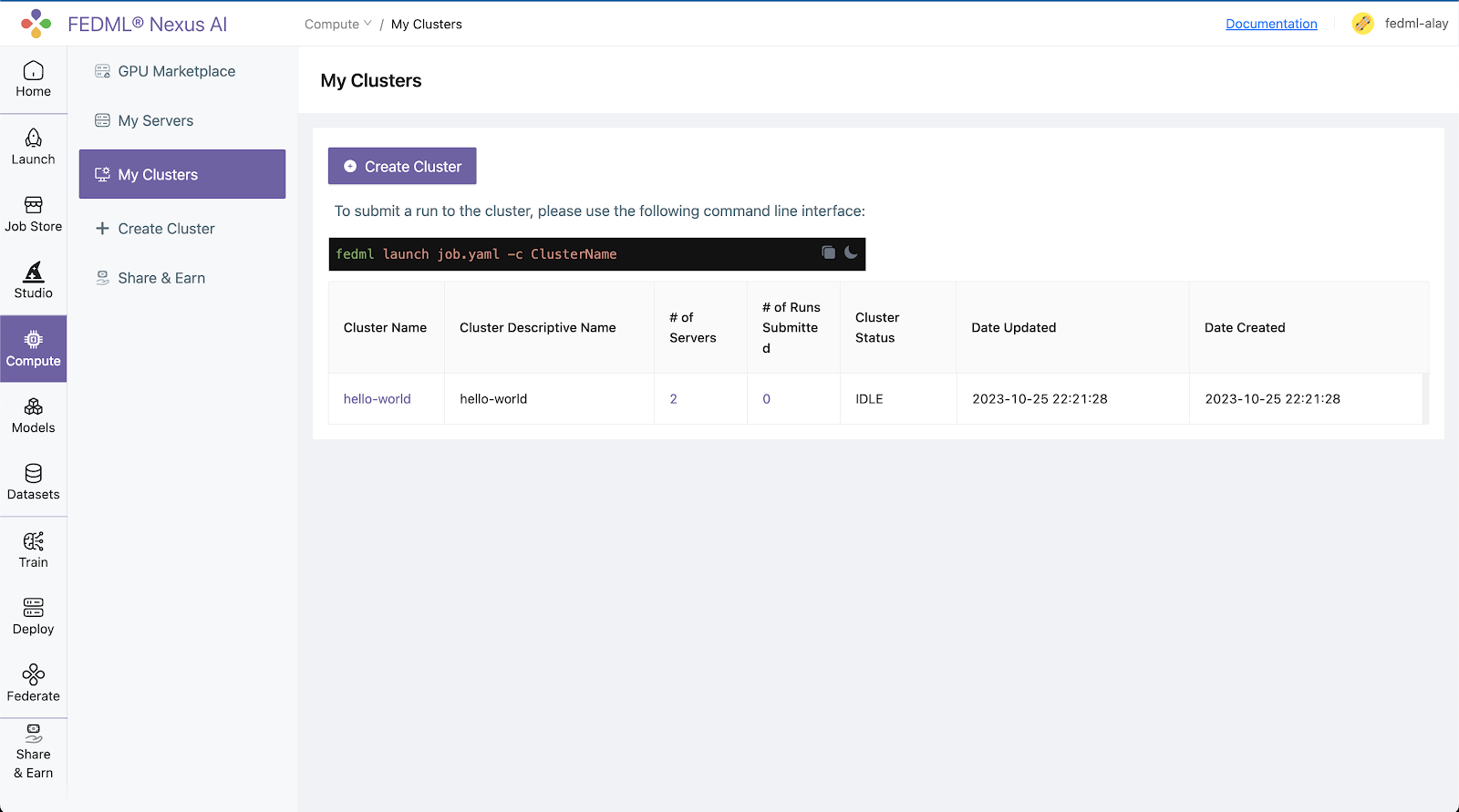
All your created clusters will be listed on the Compute / My Clusters page:
Step 4. Launch the job on your cluster:
The way to create the job YAML file is the same as “Training as a Cloud Service”. All that is left to do to launch a job to the on-premise cluster is to run following one-line command:
fedml launch job.yaml -c <cluster_name>
For our example, the command and respective output would be as follows:
fedml launch job.yaml -c hello-world
About FEDML, Inc.
FEDML is your generative AI platform at scale to enable developers and enterprises to build and commercialize their own generative AI applications easily, scalably, and economically. Its flagship product, FEDML Nexus AI, provides unique features in enterprise AI platforms, model deployment, model serving, AI agent APIs, launching training/Inference jobs on serverless/decentralized GPU cloud, experimental tracking for distributed training, federated learning, security, and privacy.