🔥 Qualcomm-TensorOpera APIs: Live in Action!
Last week, we announced our partnership with Qualcomm to provide Qualcomm Cloud AI inference solutions for LLMs and Generative AI on TensorOpera AI Platform (https://tensoropera.ai/home).
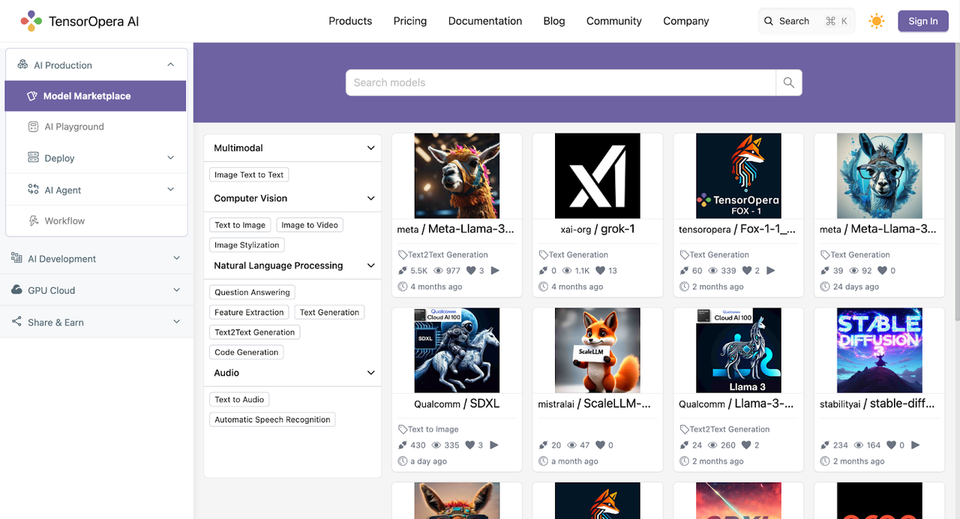
Developers can now claim their own Qualcomm-TensorOpera APIs to be able to:
1. Host dedicated endpoints for Llama3, SDXL, and other models on Qualcomm Cloud AI100
2. Autoscale end-points dynamically according to the real-time traffic
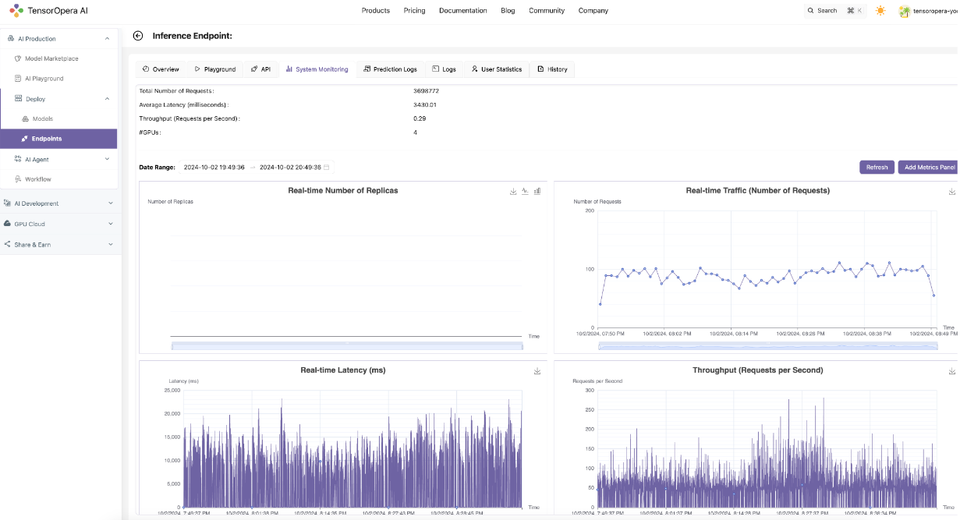
3. Access advanced observability and monitoring metrics for endpoints (# of replicas, latency, throughput, GPU/CPU utilization, etc)
4. Access prediction logs, user feedback, and usage statistics to continuously improve
Get started with your own Qualcomm-TensorOpera APIs for $0.4/GPU/hour on dedicated Qualcomm Cloud AI100, or use serverless (usage-based) at $0.05/million tokens (for Llama3-8B) and $0.00005/step (for SDXL).
Request access here: https://tensoropera.ai/qualcomm-cloud-ai-100
Support our original post on LinkedIn or Twitter.
Reach out to us via LinkedIn, Twitter, or join our Slack and Discord Channel.