
FEDML Nexus AI Unlocks LLaMA-7B Pre-Training and Fine-tuning on Geo-distributed RTX4090s
Since 2020, the machine learning (ML) community has experienced an exponential surge in large language model (LLM) sizes, escalating from 175 billion to a remarkable 10 trillion parameters in just three years. This rapid expansion has led to significant bottlenecks for AI developers, notably in the availability of GPUs, escalating compute costs, and the extended duration needed for training and improving these models.
As such, there has been a surge of research innovations in Parameter Efficient Fine Tuning (PEFT) methods, such as LoRA, which do not require fine-tuning of all parameters of the pre-trained model but only update a small portion of the parameters (task-specific parameters) while freezing most of the remaining weights. These methods have been shown to maintain task performance while substantially reducing the parameter budget needed for fine-tuning LLMs. However, they can’t be directly applied for full training (or, pre-training) of LLMs, since it is shown that training from scratch requires full-rank model training at the beginning until a low-rank subspace of the parameters is formed to reduce the optimization landscape.
This barrier was broken two weeks ago when Zhao et. al. introduced Gradient Low-rank Projection (GaLore). Their key idea was to instead leverage the slow-changing low-rank structure of the gradient of the weight matrix, rather than trying to approximate the weight matrix itself as low rank in LoRA. Interestingly, this phenomenon was also discovered and leveraged before for gradient compression to reduce the communication overhead in distributed training (e.g., GradiVeq in NeurIPS’18).
Compared to LoRA, GaLore significantly reduces optimizer states and total memory footprint by up to 82.5% and 63.3%, respectively, while maintaining training efficiency and model quality in pre-training and fine-tuning. GaLore’s central strategy involves maintaining only a compact “core” of the gradient in a dynamically adjusted low-rank subspace in optimizer memory. This approach leverages low-rank subspaces to approximate the primary trajectory of the gradient, commonly employed for complex optimization tasks such as LLM pre-training and fine-tuning. To ensure the alignment with the optimal full-rank outcome and prevent deviation, periodic recalculation of the projection is necessary. GaLore's low-rank subspaces act as a navigator, steering the descents towards the most likely direction for achieving the optimal results.
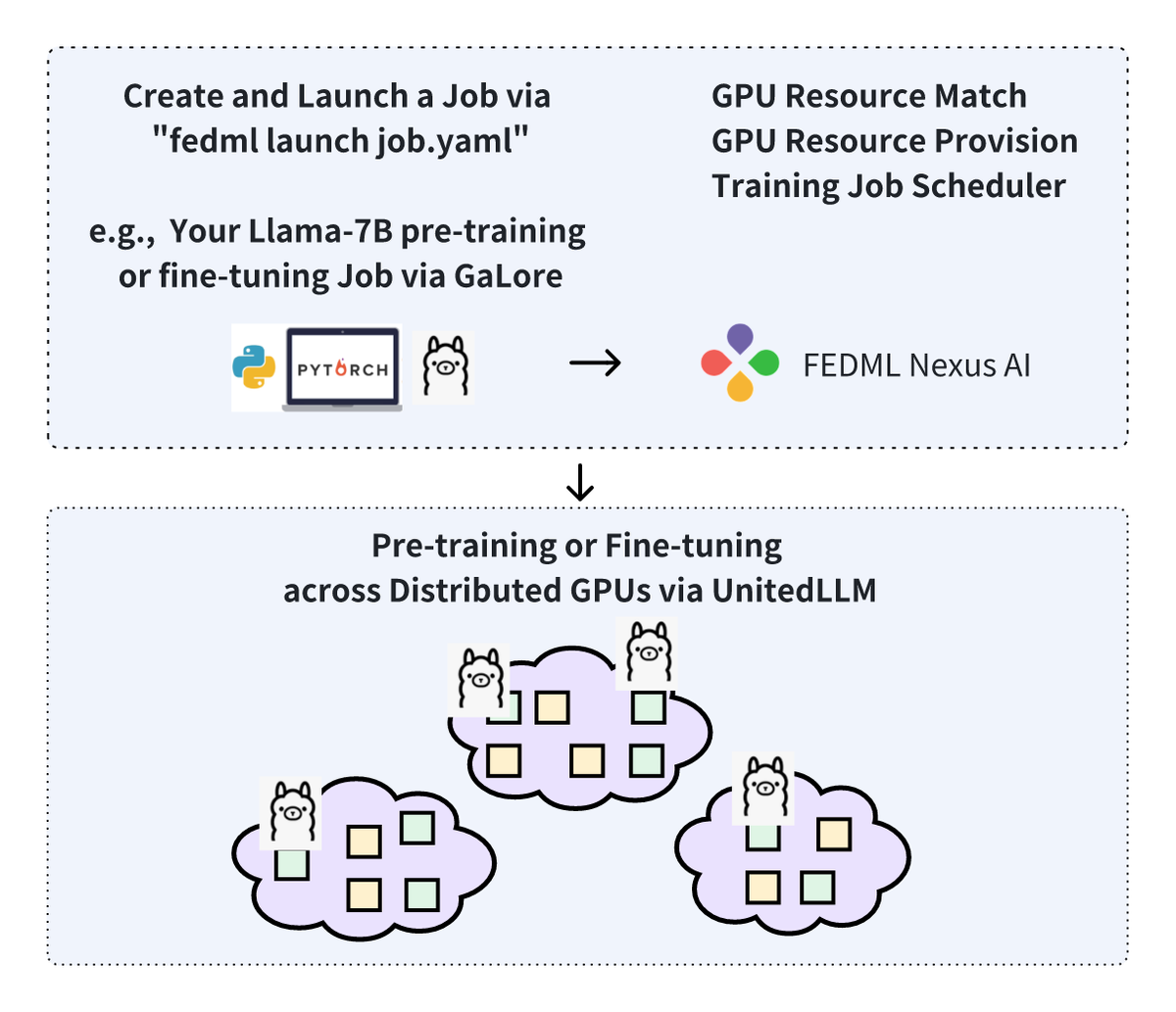
By supporting the newly developed GaLore as a ready-to-launch job in FEDML Nexus AI, we have enabled the pre-training and fine-tuning of models like LLaMA 7B with a token batch size of 256 on a single RTX 4090, without additional memory optimization.
This implies that we can train larger LLMs on a larger number of distributed GPUs than in data centers. But how can we achieve this? We further introduce FedLLM for federated learning on geo-distributed private data, and UnitedLLM for LLM pre-training and fine-tuning on decentralized community GPUs.
How to launch a GaLore Enabled training job in FEDML?
- Choose “Memory-Efficient LLM Training with GaLore” Job. Do a quick scan of the Description tab, it shows some basic usage for the code, referencing the original GaLore project's README. In the Source Code and Configuration tab, you can examine a more detailed layout and setup of the architecture.
Head to Launch > Job Store > Train
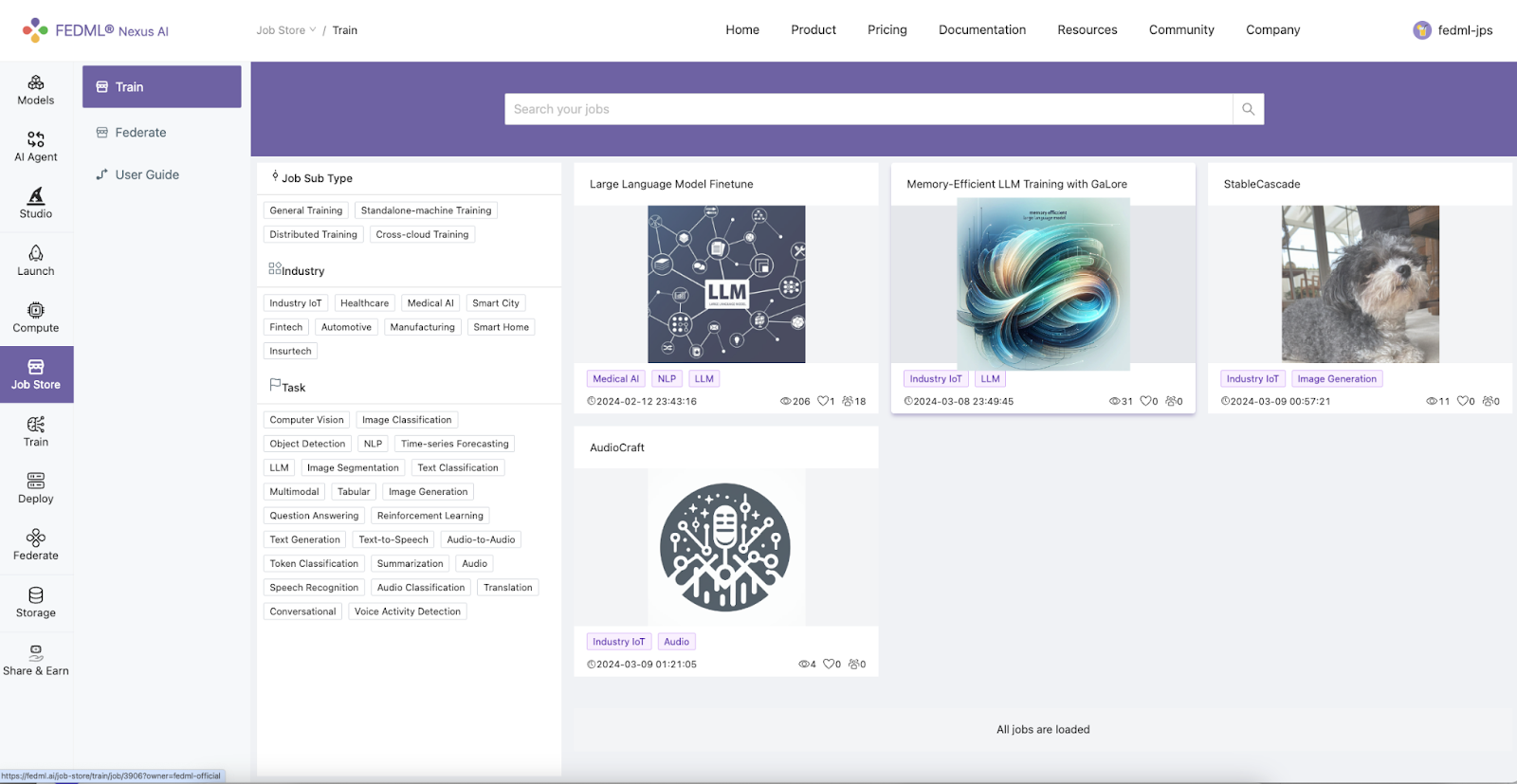
Log into FEDML Nexus AI Platform
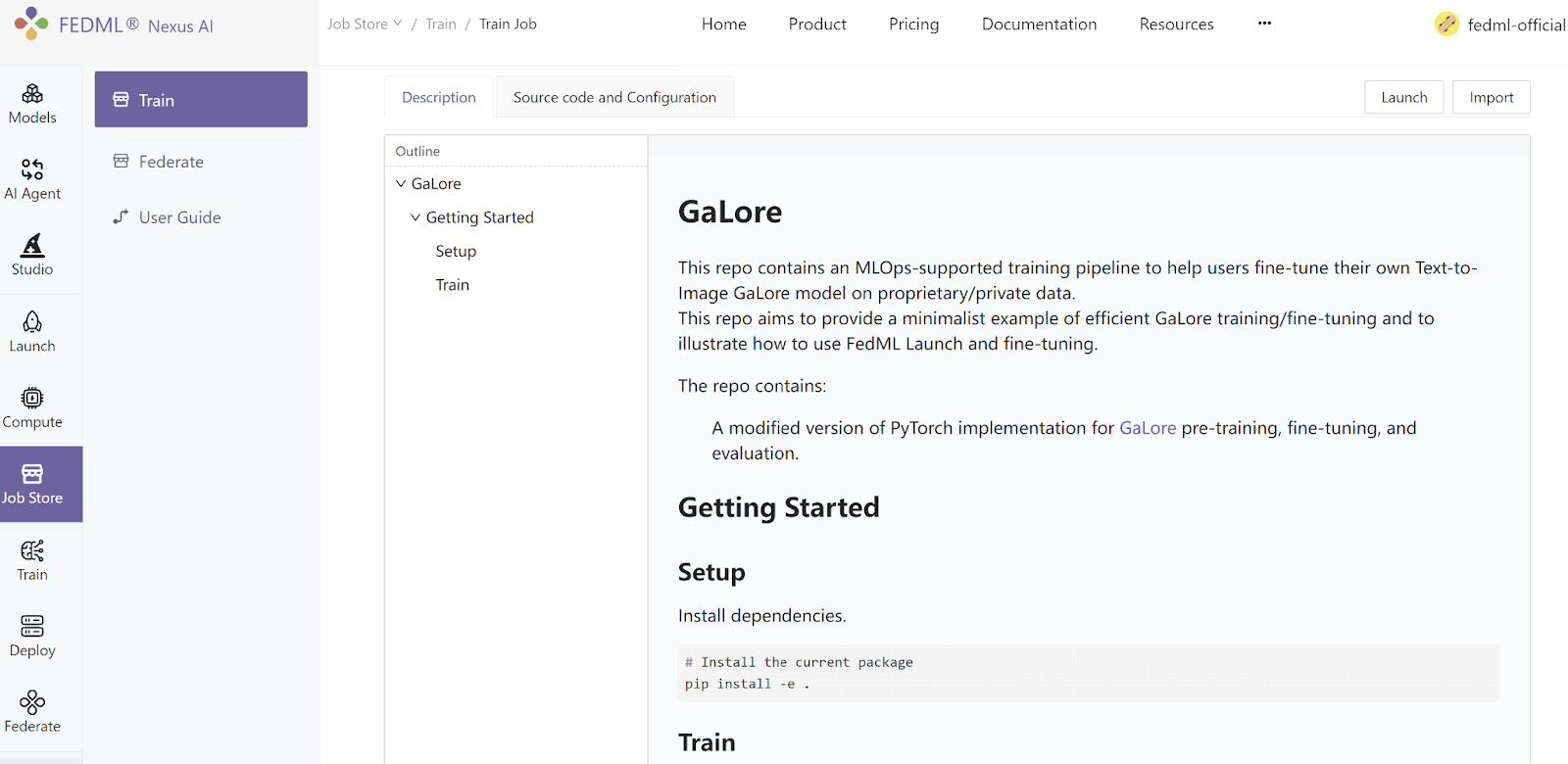
- Hit the Launch button on the top right. You will be prompted to the default configuration for the job. You could either run it as it is or customize the settings further.
For example, instead of running the default settings on A100, you could switch to RTX 3090. Under the Select Job section, click Add and replace “resource_type” to “RTX-3090” in the computing section of the job YAML file.
- Once you've finalized the hyperparameters, hit the Create button, and you should be able to launch a full-scale GaLore + Checkpointing Activation pre-training for the LLaMA 7B model with a batch size of 16.
Key run statistics showing the efficiency and scalability potential
To see your own run statistics in FEDML Nexus AI leveraging our advanced experiment tracking capabilities, go to Train > Run > Job Name to find the job you launched.
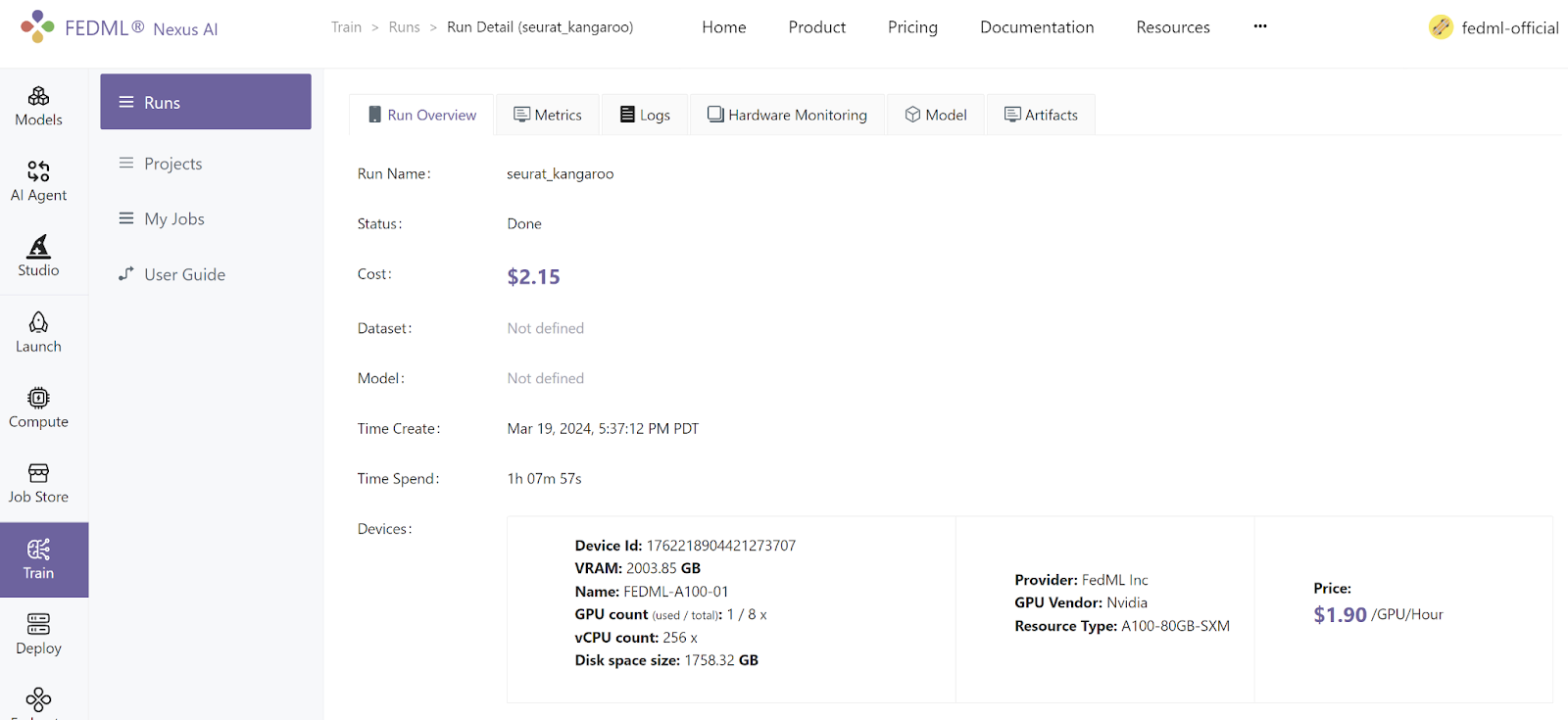
For the duration of the training, check out the GPU memory utilization in the Hardware Monitoring tab within the job run page. Look for the signs of reduced allocated GPU memory.
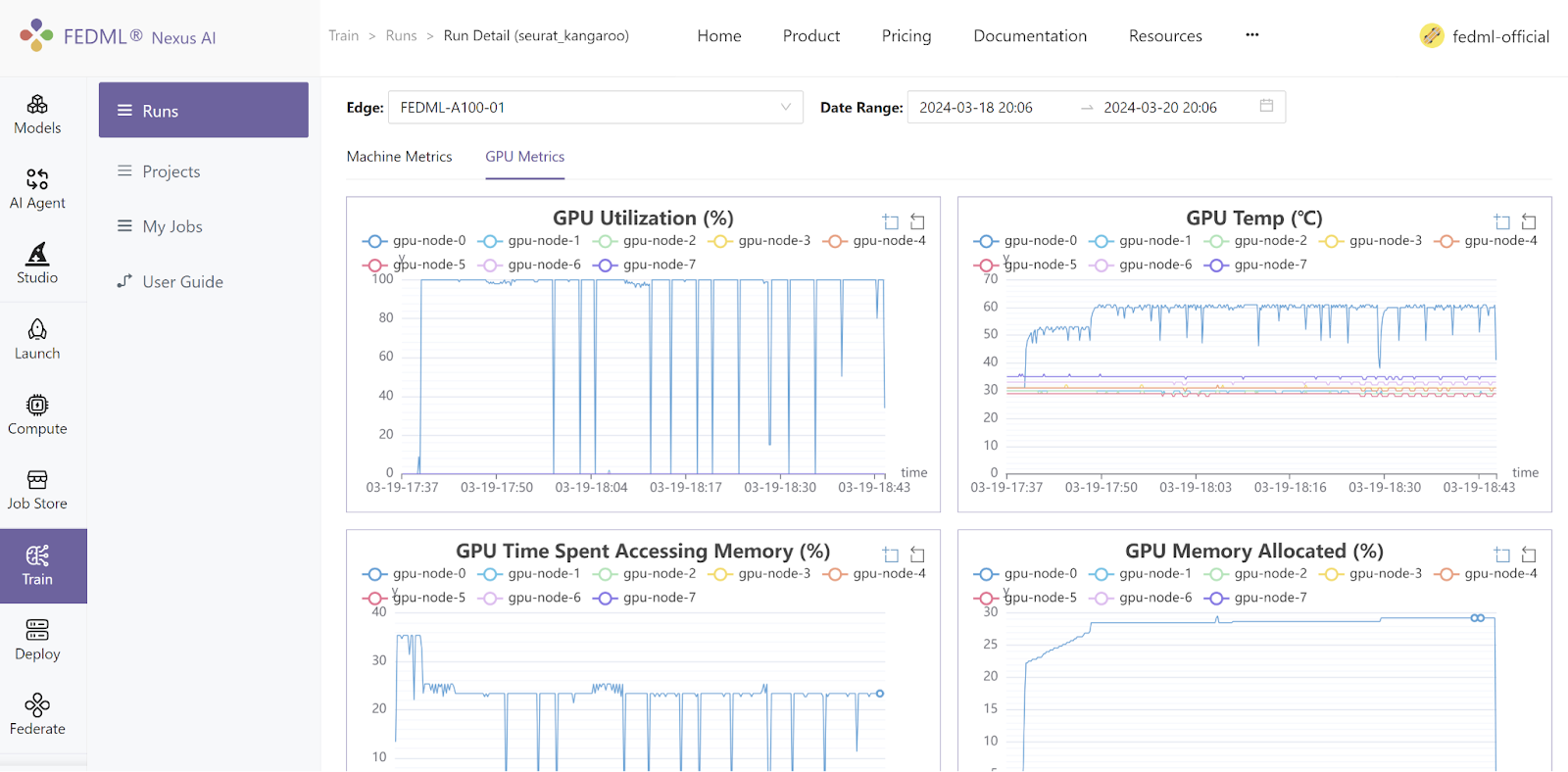
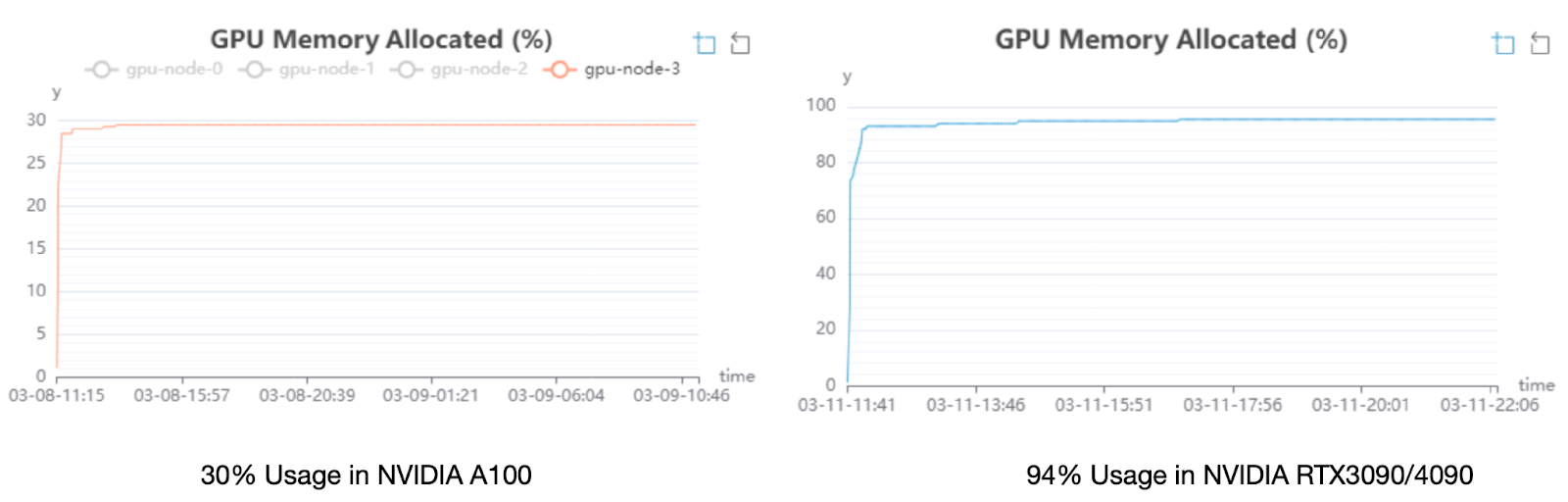
We ran experiments for GaLore + Checkpointing Activation pre-training on the LLaMA 7B model with a batch size of 16 against two different single-GPU devices: NVIDIA A100 GPU (80GB) and NVIDIA GeForce RTX 3090 GPU (24GB).
The left figure shows training on NVIDIA A100 GPU for 1100 steps over 12 hours. We saw less than 30% memory footprint throughout the course of the training. Compared to A100 GPU, training on the NVIDIA GeForce RTX 3090 GPU for 200 steps over 10 hours, we saw an expected 94% memory usage, which is reasonable given the stringent space provided on a single enthusiast-class GPU.
Have fun training and fine-tuning models with GaLore on FEDML Nexus AI platform.
More pre-built training jobs and experimental tracking features on FEDML Nexus AI?
Check out our recent blog post: https://blog.fedml.ai/train-as-a-service/.
How do we enable LLM training on distributed private data and decentralized community GPUs?
For federated learning on geo-distributed private data, please read our blog for FedLLM: https://blog.fedml.ai/releasing-fedllm-build-your-own-large-language-models-on-proprietary-data-using-the-fedml-platform/
We will also open-sourced UnitedLLM library for LLM pre-training and fine-tuning on decentralized community GPUs.
About FEDML, Inc.
FEDML is your generative AI platform at scale to enable developers and enterprises to build and commercialize their own generative AI applications easily, scalably, and economically. Its flagship product, FEDML Nexus AI, provides unique features in enterprise AI platforms, model deployment, model serving, AI agent APIs, launching training/Inference jobs on serverless/decentralized GPU cloud, experimental tracking for distributed training, federated learning, security, and privacy.FEDML, Inc. was founded in February 2022. With over 5000 platform users from 500+ universities and 100+ enterprises, FEDML is enabling organizations of all sizes to build, deploy, and commercialize their own LLMs and Al agents. The company's enterprise customers span a wide range of industries, including generative Al/LLM applications, mobile ads/recommendations, AloT (logistics/retail), healthcare, automotive, and web3. The company has raised $13.2M seed round. As a fun fact, FEDML is currently located at the Silicon Valley "Lucky building" (165 University Avenue, Palo Alto, CA), where Google, PayPal, Logitech, and many other successful companies started.