
FEDML Nexus AI Studio: an all-new zero-code LLM builder
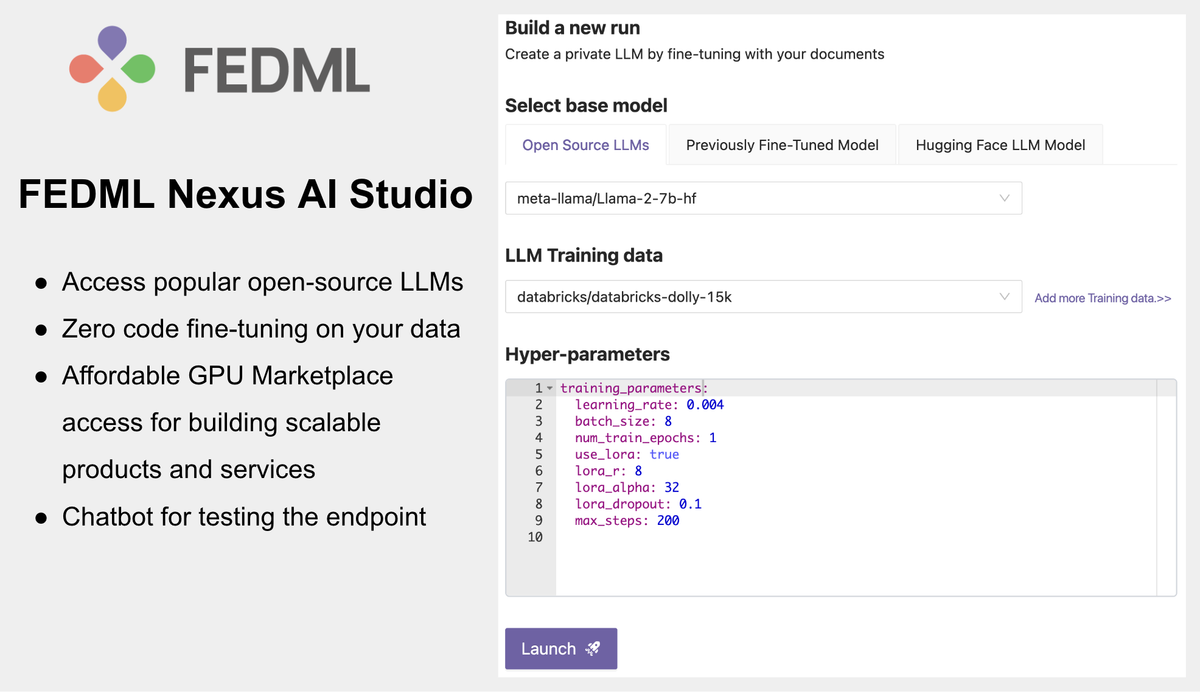
Table of contents:
Introduction
FEDML Nexus AI Overview
LLM use cases
The challenge with LLMs
Why a zero-code LLM Studio?
How does it work?
Future plans to add Studio
Advanced and custom LLM training with Launch and Train
Webinar announcement
Introduction
Most businesses today are exploring the many ways modern artificial intelligence and its generative models may revolutionize the way we interact with products and services. Artificial intelligence technology is moving fast and it can be difficult for data scientists and machine learning engineers to keep up with the new models, algorithms, and techniques emerging each week. Additionally, it’s difficult for developers to rapidly experiment with models and data at the pace required to keep up with the business’s AI application ideation.
Further, the “large” nature of these new generative models, such as large language models, is driving a new level of demand for compute, particularly, hard to find low cost GPUs, to support the massive computations required for distributed training and serving these generative models.
FEDM Nexus AI is a new platform that bridges these gaps and provides Studio, a no-code, rapid experimentation, MLOps, and low cost GPU compute resources for developers and enterprises to turn their LLM ideas into domain-specific value generating products and services.
FEDML Nexus AI Overview
FEDML Nexus AI is a platform of Next-Gen cloud services for LLMs and Generative AI. Developers need a way to quickly and easily find and provision the best GPU resources across multiple providers, minimize costs, and launch their AI jobs without worrying about tedious environment setup and management for complex generative AI workloads. Nexus AI also supports private on-prem infrastructure or hybrid cloud/on-prem. FEDML Nexus AI solves for the needs which come with generative AI development in 4 ways:
- GPU Marketplace for AI Development: Addressing the current dearth of compute nodes/GPUs arising due to the skyrocketing demand for AI models in enterprise applications, FEDML Nexus AI offers a massive GPU marketplace with over 18,000 compute nodes. Beyond partnering with prominent data centers and GPU providers, the FEDML GPU marketplace also welcomes individuals to join effortlessly via our "Share and Earn" interface.
- Unified ML Job Scheduler and GPU Manager: With a simple fedml launch your_job.yaml command, developers can instantly launch AI jobs (training, deployment, federated learning) on the most cost-effective GPU resources, without the need for tedious resource provisioning, environment setup and management. FEDML Launch supports any computing-intensive job for LLMs and generative AI, including large-scale distributed training, serverless/dedicated deployment endpoints, and large-scale similarity search in vector DB. It also enables cluster management and deployment of ML jobs on-premises, private, and hybrid clouds.
- Zero-code LLM Studio: As enterprises increasingly seek to create private, bespoke, and vertically tailored LLMs, FEDML Nexus AI Studio empowers any developer to train, fine-tune, and deploy generative AI models code-free. This Studio leverages fedml launch and allows companies to seamlessly create specialized LLMs with their proprietary data in a secure and cost-effective manner.
- Optimized MLOps and Compute Libraries for Diverse AI Jobs: Catering to advanced ML developers, FEDML Nexus AI provides powerful MLOps platforms for distributed model training, scalable model serving, and edge-based federated learning. FEDML Train offers robust distributed model training with advanced resource optimization and observability. FEDML Deploy provides MLOps for swift, auto-scaled model serving, with endpoints on decentralized cloud or on-premises. For developers looking for quick solutions, FEDML Nexus AI's Job Store houses pre-packaged compute libraries for diverse AI jobs, from training to serving to federated training.
LLM use cases
LLMs have the potential to revolutionize the way we interact with products & services. They can be used to generate text, translate languages, answer questions, and even create new creative content. Actual applications & LLM capabilities can be organized into 3 groups: Assistants, Learning, and Operations. These have some overlap of course. Some example applications in each:

The challenge with LLMs
Though new versions of open-source LLMs are released regularly, and they continuously improve, (e.g. they can handle more input context length) these based models typically won’t work well out of the box for your specific domain’s use case. This is because these base open-source models were trained on general text data from the web and other sources in their pretraining.
You will typically want to specialize the base LLM model for your domain’s use case. This entails fine-tuning the model on data that’s relevant to your use case or task. Fine-tuning, however, comes with its own set of challenges which prevent or hinder LLM projects from completing end to end.
There are 3 general challenges associated with fine-tuning large language models
- Getting access to GPU compute resources
- Training & deployment process
- Experimenting efficiently
1. compute resources: LLMs require substantial compute, memory, and time to fine-tune and deployment. The large matrix operations involved with training and deploying LLMs suggests that GPUs are in the best position to handle the calculation workload most efficiently. GPUs, particularly the high end A100 or H100 type, are very hard to find available today and can cost hundreds of thousands of dollars to purchase for on-prem.
There are techniques to efficiently use the compute, including to distribute the training across many servers, hence you will typically need access to several GPUs to run your fine-tuning.
2. process, Without a solution like FEDML Nexus AI Studio, managing and training LLM models for production scale and deployment typically involves a many step process, such as:
- Selecting the appropriate base model
- Building training data set
- Selecting an optimization algorithm
- Setting & tracking hyperparameters
- Implementing efficient training mechanisms like PEFT
- Ensure use of SOTA technology for the training
- Managing your python & training code
- Finding the necessary compute and memory.
- Distributing the training to multiple compute resources
- Managing the training and validation process
And Deploying LLM models typically involves a process like:
- Building many models to experiment with
- Building fast serving endpoints for each experiment
- Ensure use of SOTA technology for serving
- Managing your python & serving code
- Finding the necessary compute and memory.
- Connecting your endpoint with your application
- Monitoring and measuring key metrics like latency and drift
- Autoscale with demand spikes
- Failover when there are issues
FEDML Nexus AI Studio encapsulates all of the above into just a few simple steps.
3. on experimentation, there’s a fast pace of new open source model development and training techniques, and your business stakeholders are asking for timely delivery to test their AI product ideas. Hence you need a way to quickly fine-tune and deploy LLM models with a platform that automatically handles most of the steps for you, including finding low cost compute. In this way, you can run several experiments simultaneously, thereby enabling you to deliver the best AI solution and get your applications’ new value for your customers sooner.
Why a zero-code LLM Studio?
To support the 3 general challenges mentioned above, FEDML Nexus AI Studio, encapsulates a full end-to-end MLOps (or sometimes called LLMOps) for LLMs and makes the process just a few simple steps in a guided UI. The step by step is discussed in the How it works section. But as for Why LLM studio?:
- No-code: Studio’s UI walks you through few steps involved very simply
- Access to popular Open-Source LLM models: we keep track of the popular open source models so you don’t have to. We provide access to Llama 2, Pythia and others in various parameter sizes for your fine-tuning.
- Built-in training data or bring your own: We provide several industry specific data sets built-in or you can bring your own data set for the fine-tuning.
- Managing your LLM infrastructure: This includes provisioning and scaling your LLM resources, monitoring their performance, and ensuring that they are always available.
- Deploying and managing your LLM applications: This includes deploying LLM endpoints for your LLM application to run on production while collecting metrics on performance.
- Monitoring and improving your LLM models: This includes monitoring the performance of your LLM models, identifying areas where they can be improved, and retraining them to improve their accuracy.
Without a robust MLOps infrastructure like FEDML Nexus AI, it can be difficult to effectively manage and deploy LLMs. Without Studio, you may have a number of problems, including:
- Slow Development: if you can’t experiment with fine-tuning new models, new data, and configurations quickly and at low cost, you may not be putting forth the best effort model for your business applications.
- High costs: FEDML Nexus AI’s new cloud services bring a GPU marketplace based pricing, hence you can be sure your training and deployment is cost effective.
- Performance issues: If your LLM infrastructure is not properly managed, you may experience performance issues, such as slow response times and outages.
- Security vulnerabilities: If your LLM applications are not properly deployed and managed, they may be vulnerable to security attacks.
- Model drift: Over time, LLM models can become less accurate as the data they are trained on changes. If you are not monitoring and able to efficiently continuously improve your LLM models, this can lead to a decrease in the quality of your results.
How does it work?
Studio’s no-code user interface greatly compresses the typical workflow involved with fine-tuning an LLM. It’s easy and only 3 steps:
- Select an open source model, a fine-tuning data set & start training
- Select a fine-tune model and build an endpoint
- Test your model in a chatbot.
Step 1.Select an open source model, a fine-tuning data set & start training
At nexus.fedm.ai, click the Studio icon in the main menu at the left.
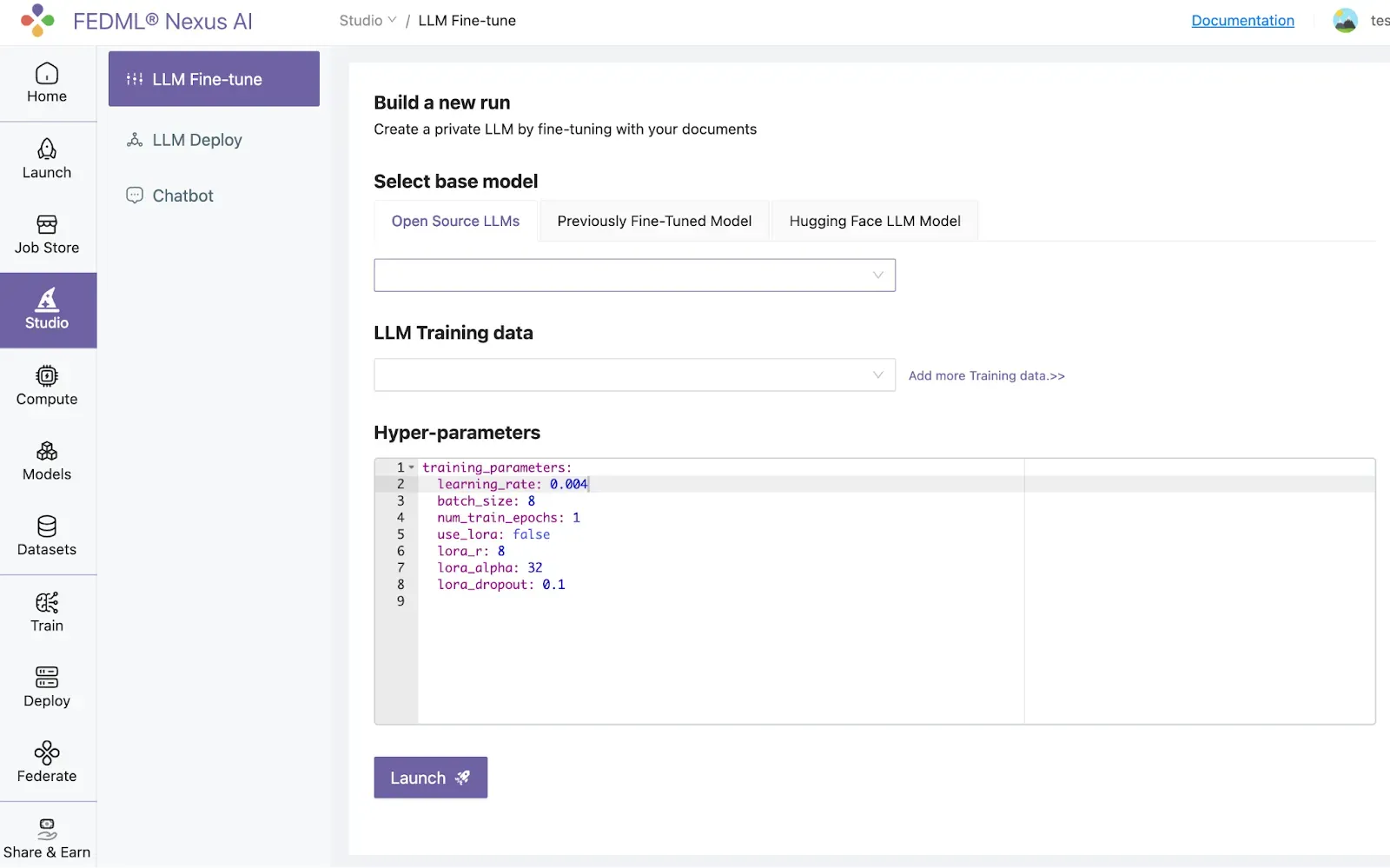
Select from our growing list of Open-source LLM modes:
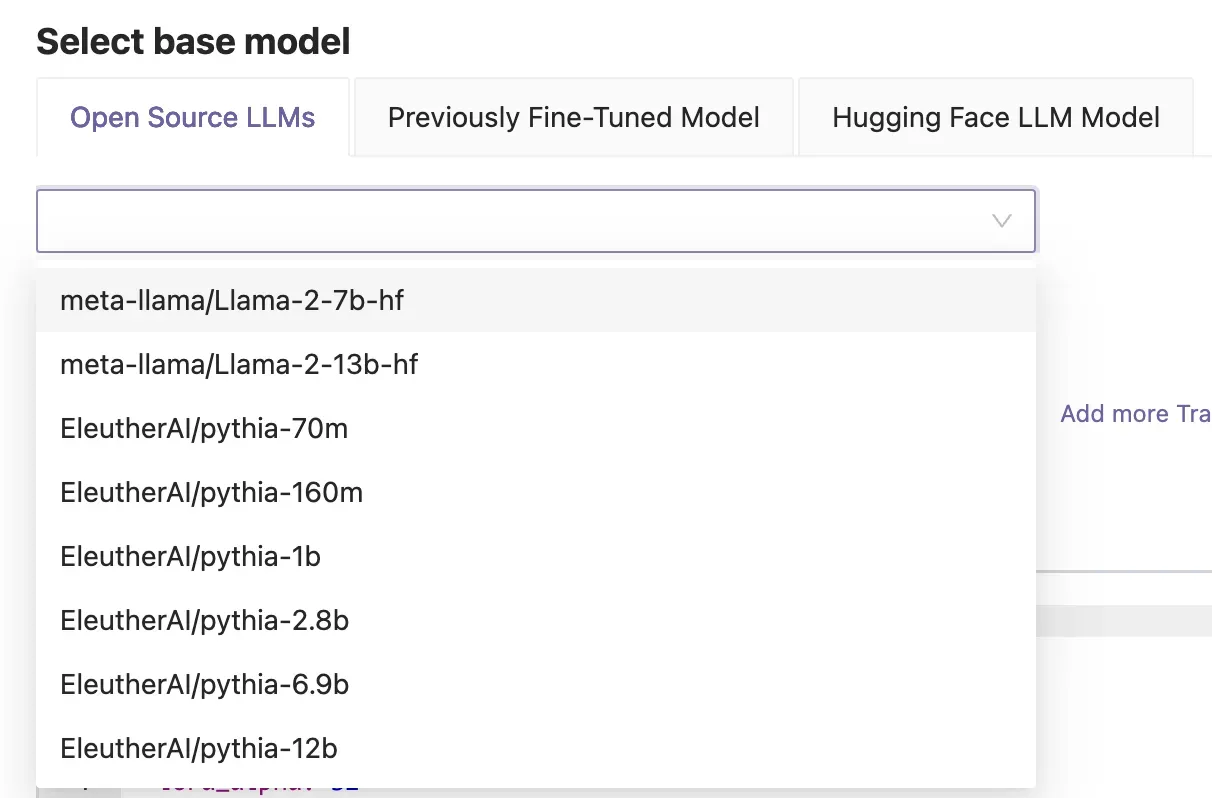
Next, select from build-in datasets or add your own. The built-in data sets are already created properly to work with the open source modes. They have the necessary design, label/columns, and the proper tokenizers are handled. You can search for an view the actual data for these standard datasets at Hugging Face, for example the popular training data databricks/databricks-dolly-15k is here: https://huggingface.co/datasets/databricks/databricks-dolly-15k/tree/main
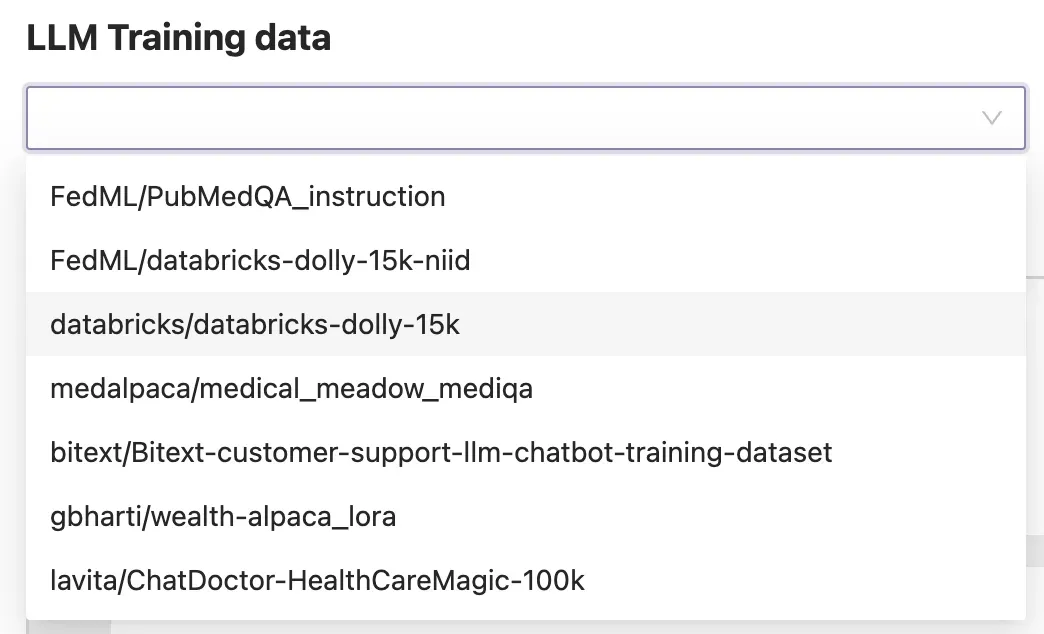
A few hyper-parameters are provided for your review and adjustment if desired. Set use_lora to true for example to drastically reduce the compute and memory needed to fine-tune.

Then click Launch, and Studio will automatically find the suitable compute in our low cost GPU marketplace to run your fine-tune training.
Studio will use a SOTA training algorithm to ensure efficient fine-tuning.
Once you start fine-tuning, you can see your model training in Training > Run
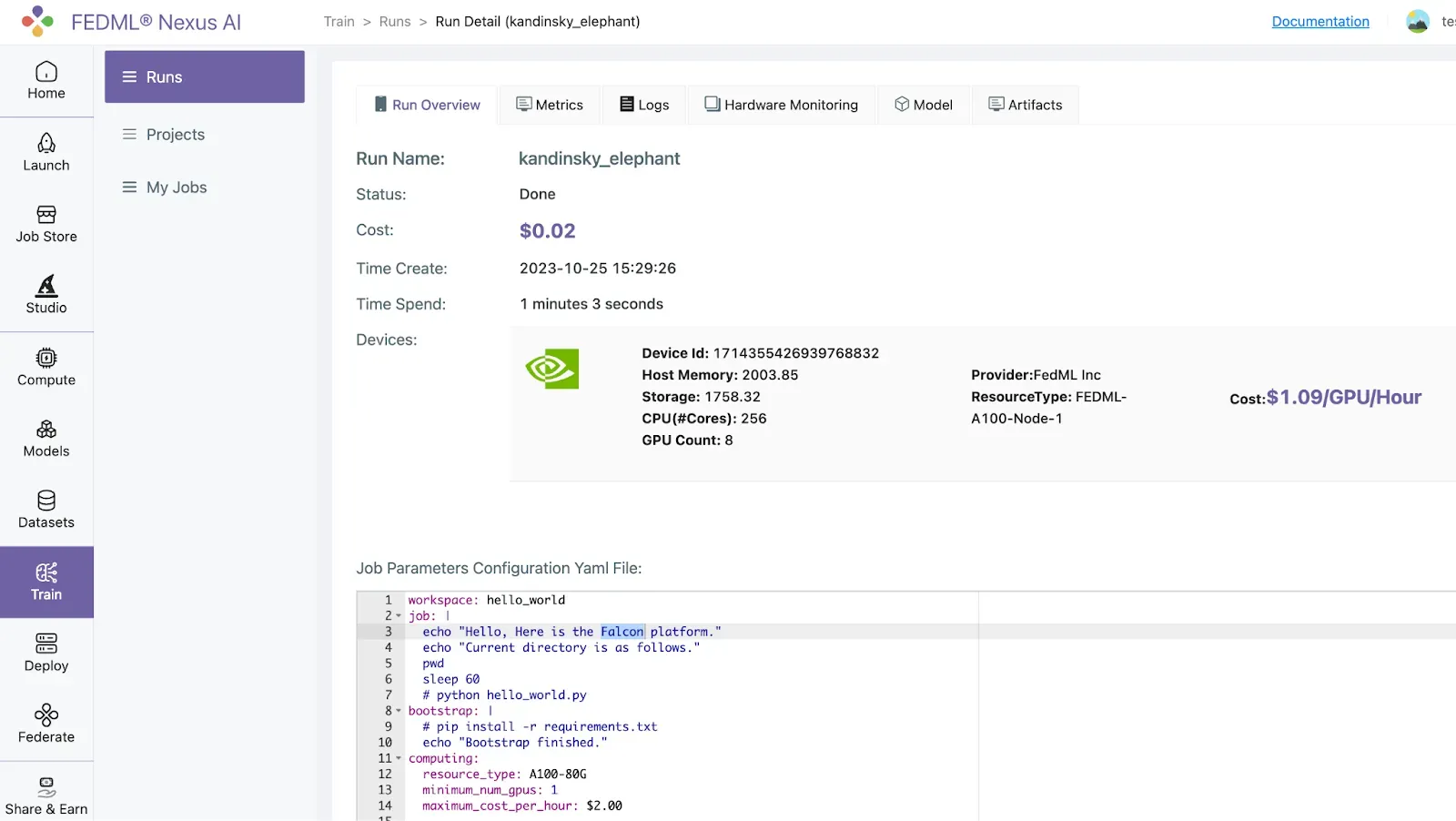
You may start multiple model fine tunes to compare and experiment with the results. The GPU marketplace will automatically find the compute resources for you. If a compute resource isn’t currently available, your job will be queued for the next available GPU.
Step 2. Select a fine-tune model and build an endpoint
After you’ve built a fine-tuned model, you can deploy it to an endpoint. Goto Studio > LLM Deploy. Name your endpoint, select your fine-tuned model and indicate FEDML Cloud for Studio to automatically find the compute resource on our GPU marketplace.
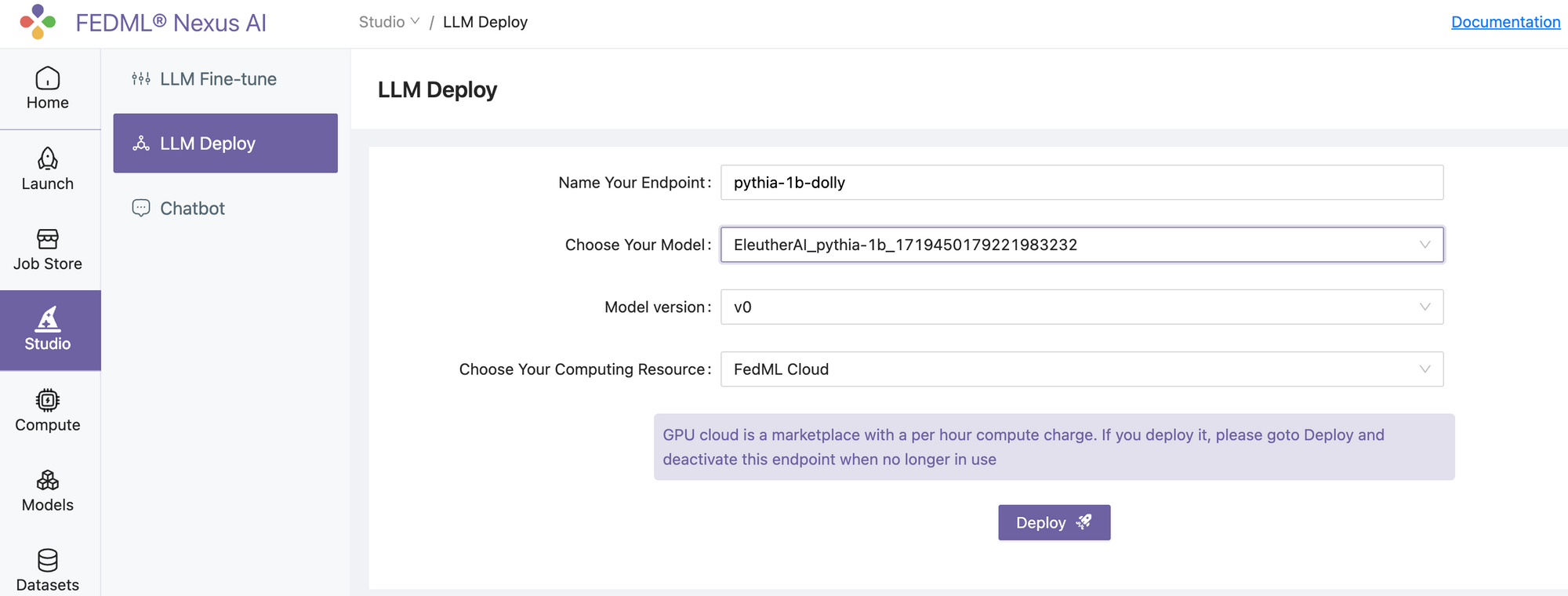
For deploy and serving, a good rule of thumb is to assume 2-bytes or half-precision is required per parameter, and hence best to have GPU memory that’s 2x number of parameters:
For example, if you have a 7 billion parameter model, at half-precision, it needs about 14GB of GPU space. Studio will automatically find a suitable GPU for you.
Step 3. Test your model in a chatbot.
And finally, test your fine-tuned LLM and its endpoint through our built-in chatbot. Goto Studio > Chatbot, select your new endpoint, and type a query to test
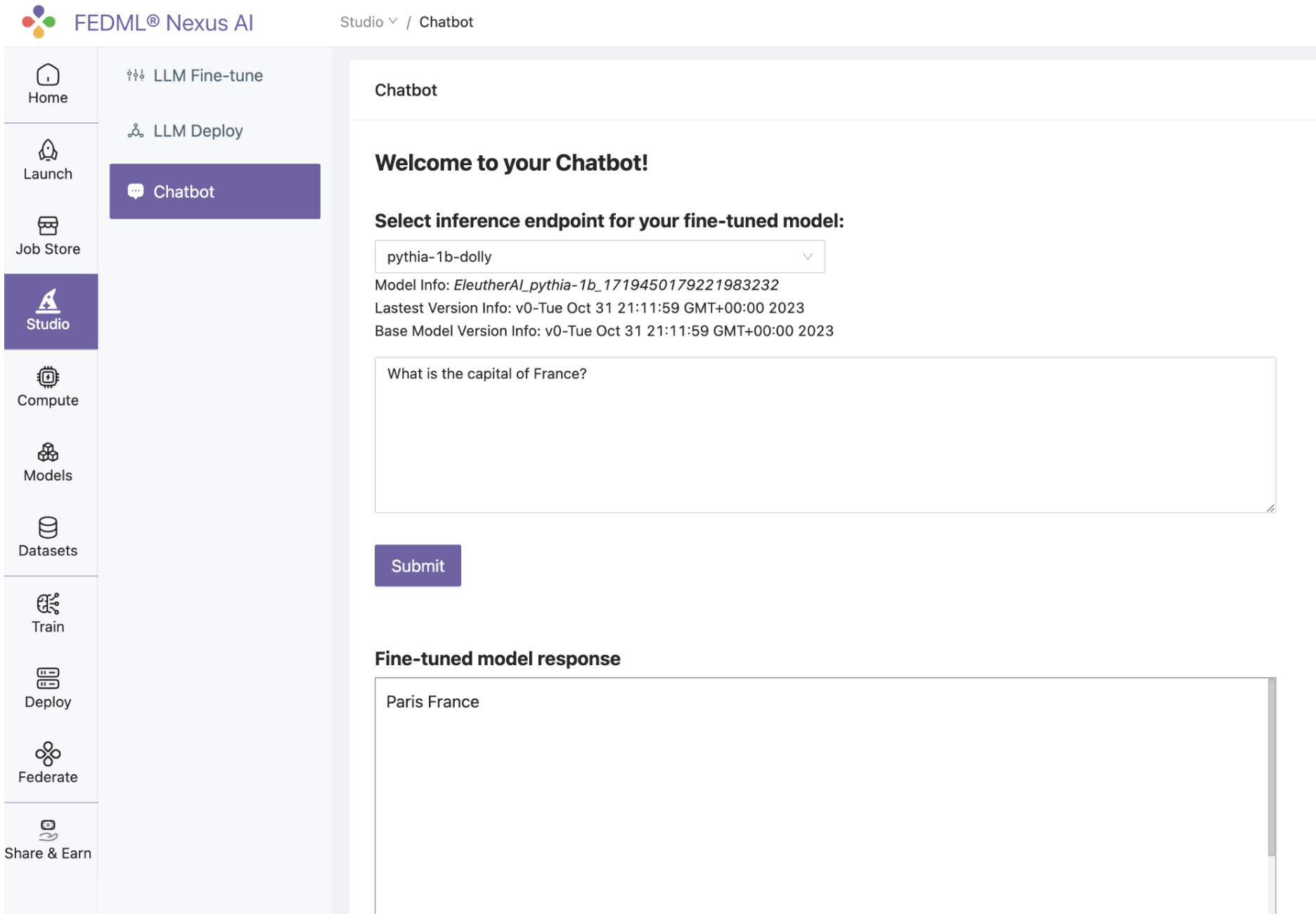
And that’s it! You’ve completed fine tuning, deployment, and a chatbot test. All with just a few clicks and Studio even found the servers for you.
FEDML also provides a more sophisticated Chatbot for customers who would like a more refined & production ready-chatbot which can support many models simultaneously.
Future plans for Studio
We plan to add additional AI training tasks to Studio. For example, Multi-modal model training and deployment. We’ll publish to our blog when those are ready for you to try.
Advanced and custom LLMs with Launch, Train, and Deploy
Check for our future blog post where we’ll show you how to handle more advanced and custom training and deployment with our Launch, Train, and Deploy products.
Webinar announcement
We have a webinar on Tuesday Nov 7 at 11am PT/2pm ET at which we’ll introduce our FEDML Nexus AI platform and show a live-demonstration of Studio:
- Discover the vision & mission of FEDML Nexus AI
- Dive deep into some of its groundbreaking features
- Learn how to build your own LLMs with no-code Studio
- Engage in a live Q&A with our expert panel